Für unsere Proxer-Backups benötigen wir eine große Menge an Speicherplatz. Bislang wurde dafür ein eigener Server mit vielen und großen Festplatten verwendet. Man sollte eine Lösung nicht komplizierter gestalten als nötig. Ein Server mit Festplatten spiegelt die einfache Lösung wider.
Allerdings stößt diese einfache Lösung an ihre Grenzen, wenn die Datenmengen „gewöhnliche“ Mengen überschreiten. Wenn sogar Festplatten mit 8-16 TB voll ausgelastet sind und es nicht mehr als vier Festplattensteckplätze pro Server gibt, gilt es, eine skalierbare Lösung zu finden, die über Jahre hinweg Bestand hat, idealerweise günstiger ist und die Wartungslast verringert.
Cloud-Speicher kann helfen, Dateien langfristig und kostengünstig zu archivieren, sodass sie bei Bedarf abrufbar sind. Den Großteil unserer Backups machen Manga-Kapitel und Videodateien aus. Hier können wir problemlos unsere Inhalte in der Cloud archivieren. Ich möchte diesen Blogpost nutzen, um ein wenig über die Vor- und Nachteile von Cloud-Speicher zu schreiben.
Cloud Storage
Bei Cloud-Speicher bezahlt man nicht für Serverhardware, Strom oder Festplatten. Man bezahlt nur für den Speicherplatz, und die Cloud-Infrastruktur ist so aufgebaut, dass man in einem Verzeichnis so viele Dateien und Ordner speichern kann, wie man möchte, und es immer der vordefinierte Preis gilt. Das macht es einfacher, die Kosten zu planen und eine Infrastruktur zu nutzen, die genau den Anforderungen entspricht.
Google Cloud Storage ist solch eine Lösung. Die Einrichtung ist unkompliziert, die Preise sind transparent.
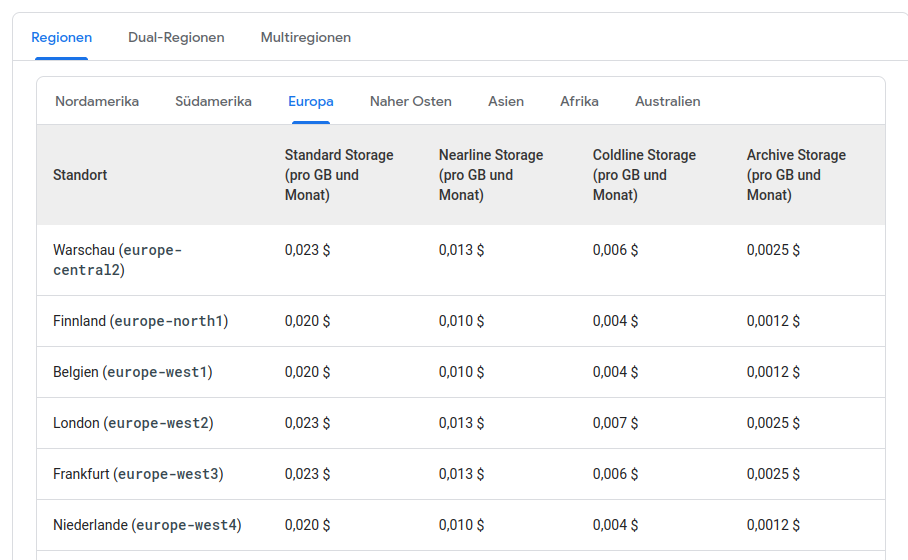
Je nach Bedarf kann man sich hier aus verschiedenen Angeboten etwas raussuchen. Für unseren Fall benötigen wir Archivspeicher in Europa. Ein einziger Standort („Region“) reicht aus. Falls man an mehreren Standorten die Speicherung durchführen möchte, kann man das auswählen („Dual-Region“, „Multiregion“). Wenn man mehrere Regionen hat, steigt dementsprechend der Preis, doch falls ein Rechenzentrum nicht erreichbar ist, so sind die Daten trotzdem sicher. In unserem Fall reicht eine einzige Region aus. Ich persönlich sehe keinen Grund, auf mehreren Regionen zu verteilen. Vor kurzem war auch ein Fall, in dem es auch bei mehreren Regionen zu einem Datenverlust kam.
Ich habe mich für das günstigste Paket in Niederlande mit dem Archive Storage entschieden. Der Preis dafür liegt bei 0,0012 € pro GB pro Monat. Bei einem TB Backupspeicher, entspricht das 1,20 €.
Es gibt einen Grund, warum die Preise so unterschiedlich sind. Je nach dem, wie „warm“ (Standard Storage) oder „kalt“ (Archive Storage) der Speicher ist, so unterscheiden sich auch die Kosten für Datenoperationen. Kalter Speicher enthält Daten, die beispielsweise höchstens 1x im Jahr aufgerufen werden und es ist nicht beabsichtigt, dass man diese Inhalte öfter herunterlädt. Bei Cloud Storage werden auch die Operationen (z.B. herunterladen, hochladen, löschen) bepreist. Diese unterscheiden sich auch je nach Region. Ich gehe hier nicht weiter auf die Details ein. Bei einer geringen Menge an Dateien können die Preise für Operationen vernachlässigt werden. Bei vielen Dateien muss dies aber auch berücksichtigt werden.
Backup-Server
Den Server zum Backuppen von Inhalten kann man nicht ganz ersetzen. Es muss schließlich eine Instanz geben, die sich mit den Datenquellen verbindet, diese verschlüsselt und diese regelmäßig im Cloud Storage ablegt. Hier kann ein virtueller Server oder ein minimales Setup genutzt werden, bei dem man temporär die Daten herunterlädt, komprimiert und verschlüsselt, und in in die Cloud hochlädt. Alle nachfolgenden Backup-Aktivitäten finden auf diesem Server statt. Ich nutze Python und Jupyter Notebook für das Ausführen der Backups. Es lässt sich gut lokal Testen und auf dem Server ausrollen.
Download
Das Herunterladen ist eine einfache Aufgabe, aber auch diese hat ihre Fallen. Es ist wichtig, dass die Inhalte zuverlässig heruntergeladen werden. Im Allgemeinen nutze ich hierfür eine Archivierung im Zip-Format. Für diesen Prozess erstelle ich spezielle Schnittstellen, die den Download der Inhalte über meinen Backup-Server ermöglichen.
Eine zusätzliche Schnittstelle muss vorhanden sein, um die Liste der Objekte bereit zu stellen. Die Dateien müssen eindeutig identifiziert werden können. Und es muss bestimmt werden können, ob ein Backup vollständig ist. Ich nutze hierfür ganz einfach die ID und die Dateigröße der Datei, die als Backup gespeichert werden soll.
Über die regulären Schnittstellen der „requests“ Bibliothek in python kommt man an Grenzen, wenn man große Dateien herunterladen möchte. Es muss mindestens so viel Hauptspeicher vorhanden sein, wie die Dateigröße ist. Bei meinem minimalen Server-Setup kann es sein, dass der Hauptspeicher geringer als 2 GB ist, die Dateien jedoch größer als 2 GB sind. Große Dateien kann man viel stabiler mithilfe von „wget“ herunterladen. Dafür habe ich selbst eine Funktion gebaut.
import subprocess
def download_file_wget(url, output_path):
try:
subprocess.run(["wget", "-O", output_path, url], check=True, stdout = subprocess.DEVNULL)
print("Download completed successfully.")
return True
except subprocess.CalledProcessError as e:
print(f"Error downloading file: {e}")
return FalseDiese Funktion erlaubt das Herunterladen auch großer Dateien, ohne dass man den Hauptspeicher berücksichtigen muss.
Komprimierung
Backups nehmen meistens mehr Speicherplatz in Anspruch, als sie müssten. Es lässt sich einiges an Speicherplatz und damit an Geld sparen, wenn man die Backups vor dem Hochladen komprimiert.
Der Vorteil von Komprimierung ist, dass die selben Dateien so viel kleinere Speichergrößen beanspruchen. Der Nachteil von Komprimierung kommt dann zu tragen, wenn man Dateien wiederherstellen möchte. Beim Entpacken muss zusätzlich Zeit in Anspruch genommen werden, damit die Datei wieder hergestellt werden kann. Dies ist jedoch in den meisten Fällen kein Problem.
Verschlüsselung
Ich bin abgeneigt gegen den Gedanken, wertvollen Daten bei einem Cloud Anbieter unverschlüsselt abzulegen. Backups können im Falle von Datenbankbackups datenschutzrelevante oder vertrauliche Inhalte beinhalten. Die Komprimierung und Verschlüsselung erfolgt über den folgenden Befehl.
subprocess.run('tar -cvzf - '+source_file+' | gpg -c --passphrase '+encryption_key+' --batch > '+target_file, check=True, capture_output=True, shell=True)Ein Schlüssel wird über die Encryption-Key übergeben. Der Vorteil der Verschlüsselung besteht darin, dass die Dateien für den Cloud-Anbieter „unlesbar“ gemacht werden können, während weiterhin deren Dienste genutzt werden. Vertrauliche Inhalte behalten ihre Vertraulichkeit. Der Nachteil hier ist ähnlich wie bei der Komprimierung, dass die Entschlüsselung etwas Zeit in Anspruch nimmt.
Upload
Die betroffenen Dateien werden in das Zielverzeichnis im Cloud-Storage abgelegt.
def upload_blob(bucket_name, source_file_name, destination_blob_name):
"""Uploads a file to the bucket."""
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(destination_blob_name)
generation_match_precondition = 0
blob.upload_from_filename(source_file_name, if_generation_match=generation_match_precondition)
print(
f"File {source_file_name} uploaded to {destination_blob_name}."
)Diese Uploadfunktion berücksichtigt nicht, ob die Datei im Zielverzeichnis bereits existiert. Existiert eine Datei bereits, wird ein Fehler ausgelöst. Damit existierende Dateien übersprungen werden, muss zusätzliche Logik eingebaut werden.
Bericht
Bei einer großen Menge an Daten ist es entscheidend, dass durchgehend aktuelle Berichte vorliegen, die über die vorhandenen Backups informieren. Es handelt sich um eine Art Inventur der existierenden Backups. Mithilfe der Storage Insights-Inventarberichte kann nächtlich eine Inventardatei angelegt werden. Beim Durchführen der Backups kann diese Datei geprüft werden, um die Vollständigkeit der Backups zu prüfen.
Kosten
Insgesamt werden etwa 24TB an Backups gespeichert. Die Kosten dafür belaufen sich auf etwa 26€.
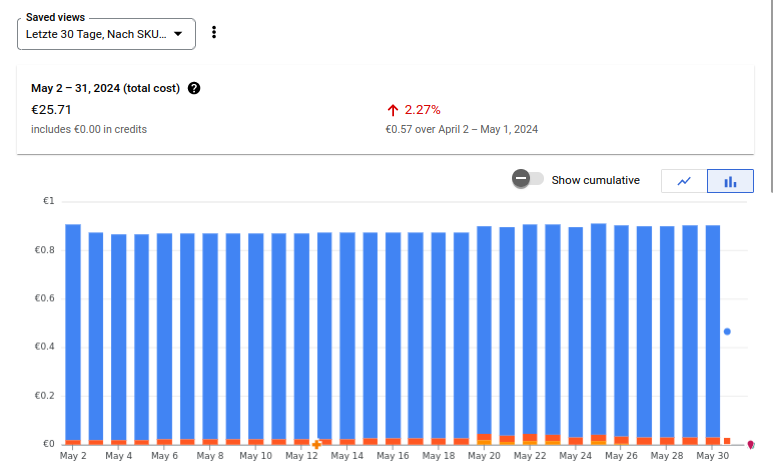
Damit ist der Preis für die Backups mehr als 100€ geringer als in der ursprünglichen Lösung.
Fazit
Der Wechsel auf Cloud Storage kann die Kosten für Backups deutlich senken. Mithilfe von Verschlüsselung ist es möglich die Inhalte für den Cloud Anbieter unleserlich zu machen. Mithilfe von Komprimierung lassen sich Inhalte noch weiter verkleinern um die Kosten noch weiter zu senken.
Das Cloud Geschäftsmodell kann genau den Bedarf erfüllen, der nötig ist, damit Anforderungen an Backups erfüllt werden. Mithilfe von Dualregionen oder Multiregionen lassen sich Backups auf mehrere Regionen verteilen.
Insgesamt kann Cloud Speicherplatz eine große Chance darstellen, die Kosten zu senken und die Effizienz zu erhöhen. Es ist jedoch erforderlich, kritisch mit Cloud-Speicher umzugehen. Das Speichern von Daten ist einfach, aber die sichere Speicherung erfordert zusätzliche Anstrengungen. Um unerwartete Kostenerhöhungen für Operationen und Speicherplatztypen zu vermeiden, muss eine sorgfältige Planung der Backups durchgeführt werden.