Data-Science ist genauso eine Kunst und Fähigkeit wie Software-Entwicklung. Data-Science erfordert Kenntnisse aus der Software-Entwicklung, Betriebswirtschaft und Mathematik, um aus Daten Wert zu schöpfen. Ich hatte ja bereits SAP Analytics Cloud (SAC) vorgestellt. Heute will ich ein weiteres Tool aus dem Hause SAP vorstellen, was bei Data-Science-Themen unterstützen kann. Es ist die SAP Data Warehouse Cloud (DWC).
Wer DWC zum Ersten Mal öffnet, und bereits SAC kennt, wird erkennen, dass vieles ähnlich aussieht. Tatsächlich überlappen sich teilweise die Funktionalitäten beider Anwendungen. Und doch sind die Stärken beider Anwendungen sehr unterschiedlich.
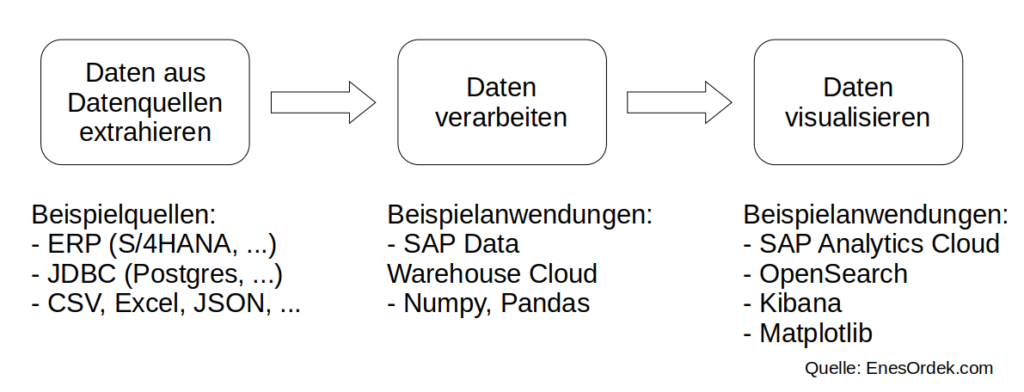
Wenn man sich eine einfache Data Pipeline vor Augen führt, so gibt es verschiedene Tools, die in unterschiedlichen Phasen eingesetzt werden. Es müssen die Datenquellen ausgewählt und Daten daraus extrahiert werden. Die extrahierten Daten müssen verarbeitet werden und anschließend visualisiert werden. Während sich SAC bei der „Datenvisualisierung“ befinden würde, wäre DWC bei der „Datenverarbeitung“ ansässig.
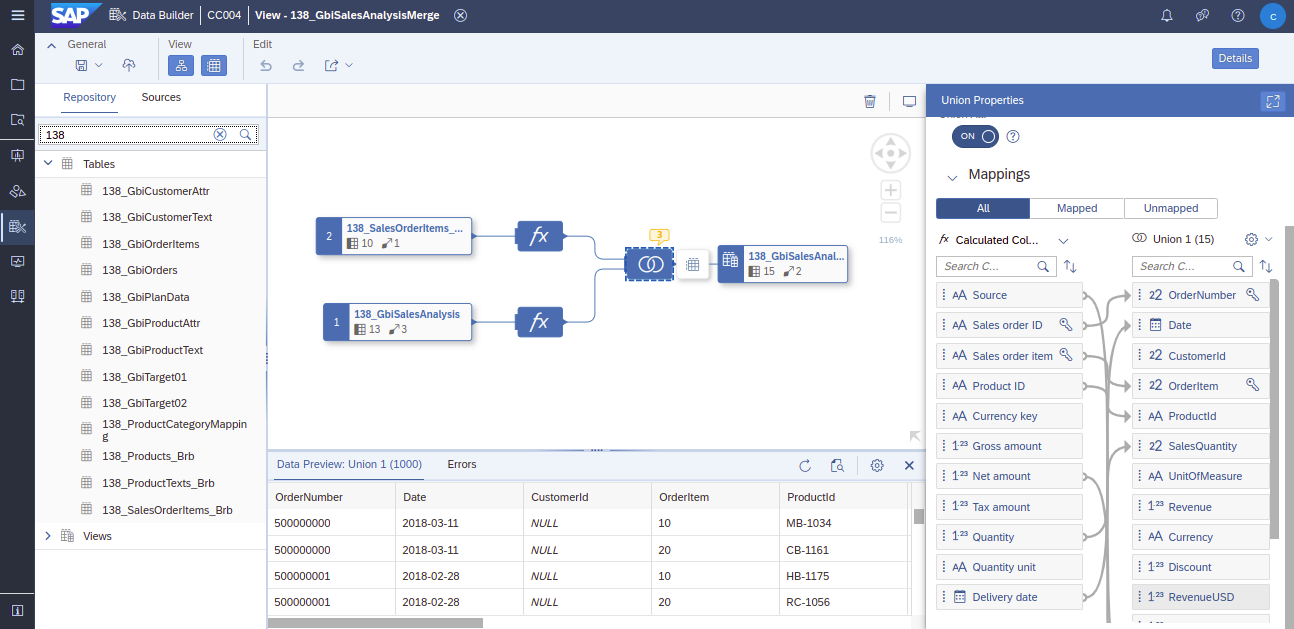
In diesem Screenshot ist sehr gut solch eine einfache Datenverarbeitung in DWC in visueller Form zu sehen. Ich kann mehrere Datenquellen einbinden, Funktionen an diesen Anwenden, sie miteinander kombinieren (z.B. über JOIN oder UNION) und das Ergebnis als eine neue konsumierbare Datenquelle freigeben. Auf ein paar Aspekte von DWC möchte ich etwas detaillierter eingehen.
Datenquellen
Daten können über die Connectoren aus verschiedenen Quellen importiert werden. Es können einfache Dokumente (wie JSON, XML, …) importiert werden. Es können auch Daten aus Postgres über den JDBC Connector importiert werden. Eine vollständige Auflistung findet sich hier.
Data Flow
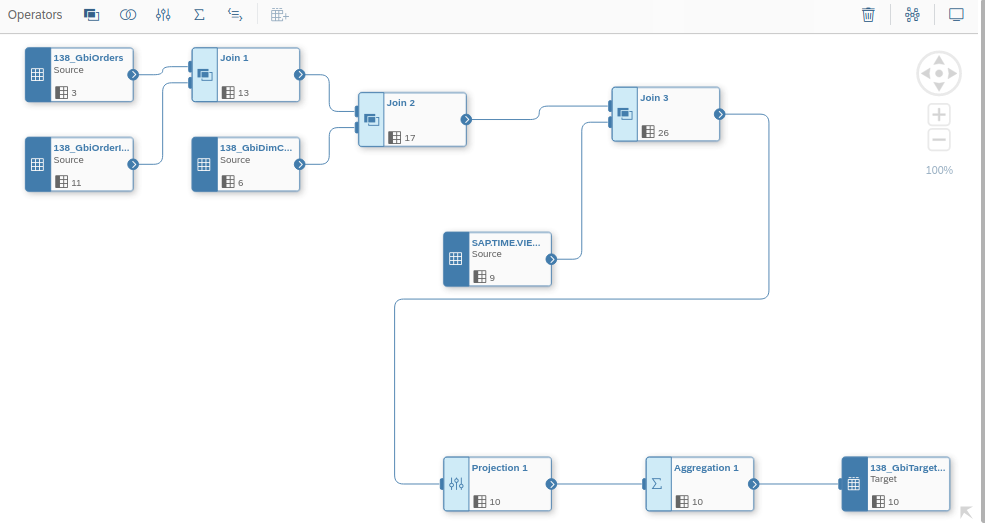
Nach dem Import kann als erstes ein Data Flow genutzt werden, um die Daten in beliebiger Art und Weise zu verändern und nutzbar zu machen. Hier sind der Fantasie keine Grenzen gesetzt.
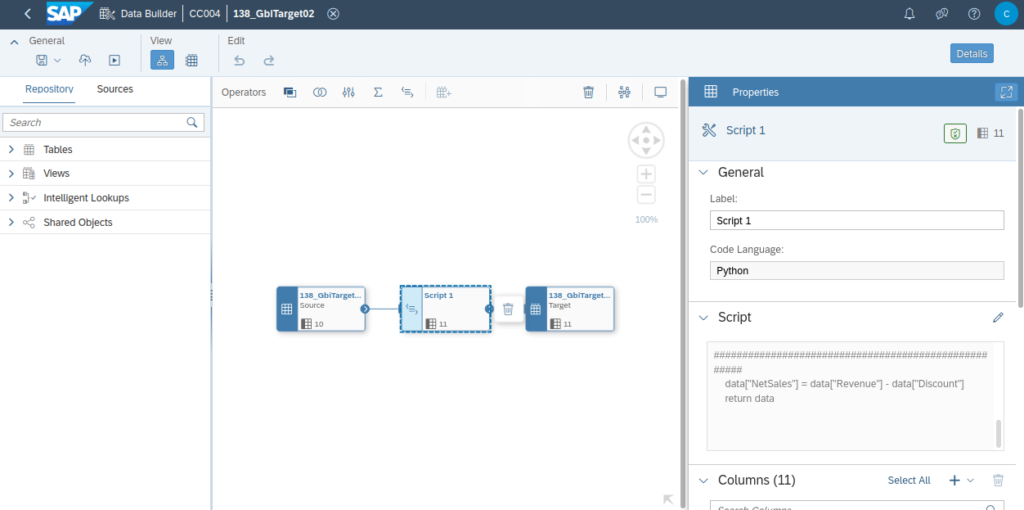
Es kann auch Python Scripting auf die Daten angewendet werden. Ich habe das in diesem Screenshot beispielhaft getan. Numpy und Pandas sind hier von Haus aus ebenfalls mit enthalten.
Data Flows eignen sich dafür komplexe Verarbeitung der Daten durchzuführen. Nach dem Speichern und Anwenden (Deployment) des Data Flows kann es dauern, bis erste Previews der Daten vorhanden sind. Danach sind auch an allen Stellen eine Vorschau der Daten verfügbar, sodass man auch sieht, wie sich die Daten nach einer Operation verändert haben.
Damit Daten aus Data Flows visualisiert werden können, muss basierend auf diesen eine View erzeugt werden. Falls man keine komplexen Operationen auf den Daten benötigt, kann man auf Data Flows verzichten und auch einzig Views verwenden.
(Graphical) Views
Es ist möglich, über Views Daten zu verändern. Views erlauben zum Teil ähnliche Operationen wie Data Flows. Der entscheidende Unterschied ist aber, dass man bei Views keine komplexen Transformationen anwenden kann. So ist kein Python Scripting und keine Projektionen verfügbar. Views kann man sich ähnlich wie Views in relationalen Datenbanken vorstellen. Veränderungen der Daten werden in dem Moment angewendet, in dem sie eingelesen werden und sind sofort verfügbar. Aus diesem Grund ist bei Views die Datenvorschau zu jedem Zeitpunkt, auch vor dem Speichern und Anwenden (Deployment) verfügbar.
DWC erlaubt, alle Views visualisierbar zu machen. Dafür müssen diese „Consumable“, d.h. „konsumierbar“ eingestellt werden.
Visualisierung
Für die Visualisierung besitzt DWC einen Story Builder. Dieser ist jedoch nicht geeignet für produktive Visualisierungen. Es erlaubt einen Einblick in die Daten.
DWC hat von Haus aus eine gute Integration mit SAC. Consumable Views können darin visualisiert werden.
Fazit
Gemeinsam mit SAC ist DWC ein großartiges Data-Science Werkzeug, was bei der Verarbeitung und Darstellung von Daten behilflich ist. Was man vorher in Pandas und Numpy durchgeführt hat, kann man nun mithilfe einer intuitiven grafischen Oberfläche in DWC durchführen. Die Daten kann man im Anschluss für SAC bereitstellen und darstellen.
Es ist möglich, für Data-Science Prototypen oder Experimente weiterhin Tools wie Pandas oder Numpy zu nutzen. Es erfordert Entwicklungsaufwand und es ist bedingt für Nicht-Entwickler geeignet. Alle Unternehmen, die irgendwo Daten sammeln und nützlich machen wollen, müssen daher meiner Ansicht nach irgendwie ihre Data-Science Aufgaben skalieren. Beide Werkzeuge sind ausgereifte Produkte und erlauben diese Skalierbarkeit für Unternehmen.