SAP HANA ist die Datenbanklösung von SAP, die eine breite Palette an Möglichkeiten und Funktionen für Geschäftsanwendungen bieten. Was vielleicht weniger bekannt ist, dass diese Datenbank auch Integration in offene Connectoren wie JDBC oder ODBC APIs anbietet, sodass man aus jeder beliebigen Anwendung heraus Operationen auf der Datenbank ausführen kann.
Vor Kurzem habe ich im Rahmen von Data-Science Aufgaben diese Connectoren genutzt und möchte hier dokumentieren, wie man Operationen in SAP HANA von Jupyter Notebook aus durchführen kann. Es ist dadurch möglich von bestehenden Data-Science Werkzeugen gebrauch zu machen und gleichzeitig von den Möglichkeiten zu profitieren, die SAP HANA für Geschäftsanwendungen bietet. Ich möchte das Ganze in diesem Beitrag an einem Beispiel erläutern.
Das Ergebnis dieser Arbeit findet sich auch auf GitHub.
Update: Blog Artikel gibt es nun auch auf englisch auf blogs.sap.com
SAP HANA
Jürgen Müller hat SAP HANA in einem Blogbeitrag näher erläutert, was SAP HANA so ausmacht. Ich will es auch in eigenen Worten ein wenig zusammenfassen. SAP HANA ist eine In-Memory Datenbank, die insbesondere für analytische Anwendungsfälle große Vorteile verschafft. Sie verbindet viele Eigenschaften der relationalen Datenbanken, aber auch der NoSQL-Datenbanken (z.B. Spaltenorientierte Eigenschaft) in einem einzigen Datenbanksystem. Je nach Anwendungsfall können Eigenschaften aktiviert oder deaktiviert werden, um so für jeden Anwendungsfall die beste Leistung zu bekommen.
SAP HANA ist das Backend vieler SAP Anwendungen. So baut S/4HANA im Hintergrund auch auf SAP HANA auf und nutzt dies als Datenbank. In der SAP Business Technology Platform (BTP) ist HANA die erste Wahl, wenn es um Persistierung von Daten geht. Mit CAP CDS wird hier beispielsweise ein großartiges Werkzeug für Datenbankmodellierung angeboten. Auch SAP Data Warehouse Cloud und SAP Analytics Cloud nutzen SAP HANA als Datenbank.
Im Feature Scope kann man im Detail über die Features sich erkundigen.
Jupyter Notebook
Jupyter Notebook ist neben der Programmiersprache R das Werkzeug der Wahl, wenn es darum geht, Herausforderungen der Data-Science anzugehen. In Jupyter Notebook werden DataFrames genutzt. DataFrames haben Schnittstellen mit anderen Bibliotheken wie numpy, sodass viele mathematische Operationen auf diesen angewendet werden können.
DBeaver
Für den Zugang zu Datenbanken nutze ich gerne DBeaver. DBeaver ist eine graphische Oberfläche um Inhalte von Datenbanken anzuschauen und diese ggf. zu verändern.

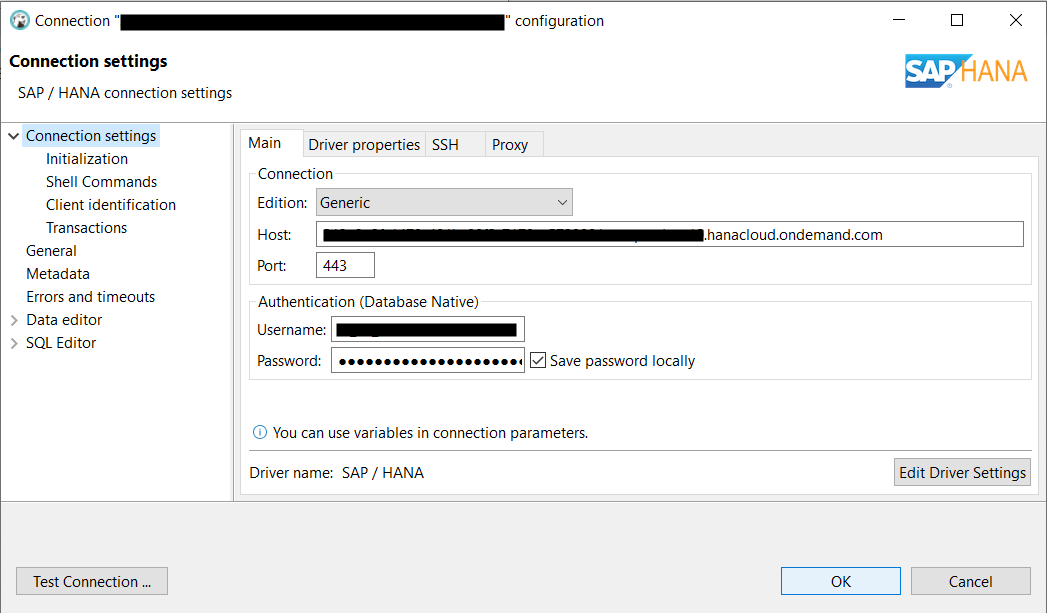
DBeaver unterstützt auch SAP HANA. Es lässt sich über das Menü auswählen und mit den Zugangsdaten konfigurieren. DBeaver ist vergleichbar mit phpmyadmin, MysqlWorkbench oder pgAdmin.
Beispiel
Ich will in diesem Beitrag anhand eines Beispiels darstellen, wie Daten aus Jupyter Notebook in SAP HANA persistiert werden können.
Daten
Ich will als Datensatz wieder den Bevölkerungsbestand von Mannheim nutzen. Dieser Datensatz beinhaltet von 2009 bis 2020 die Anzahl der Personen pro Stadtteil. Das ist auch der selbe Datensatz, den ich in einem anderen Projekt bereits analysiert hatte.
Daten einlesen
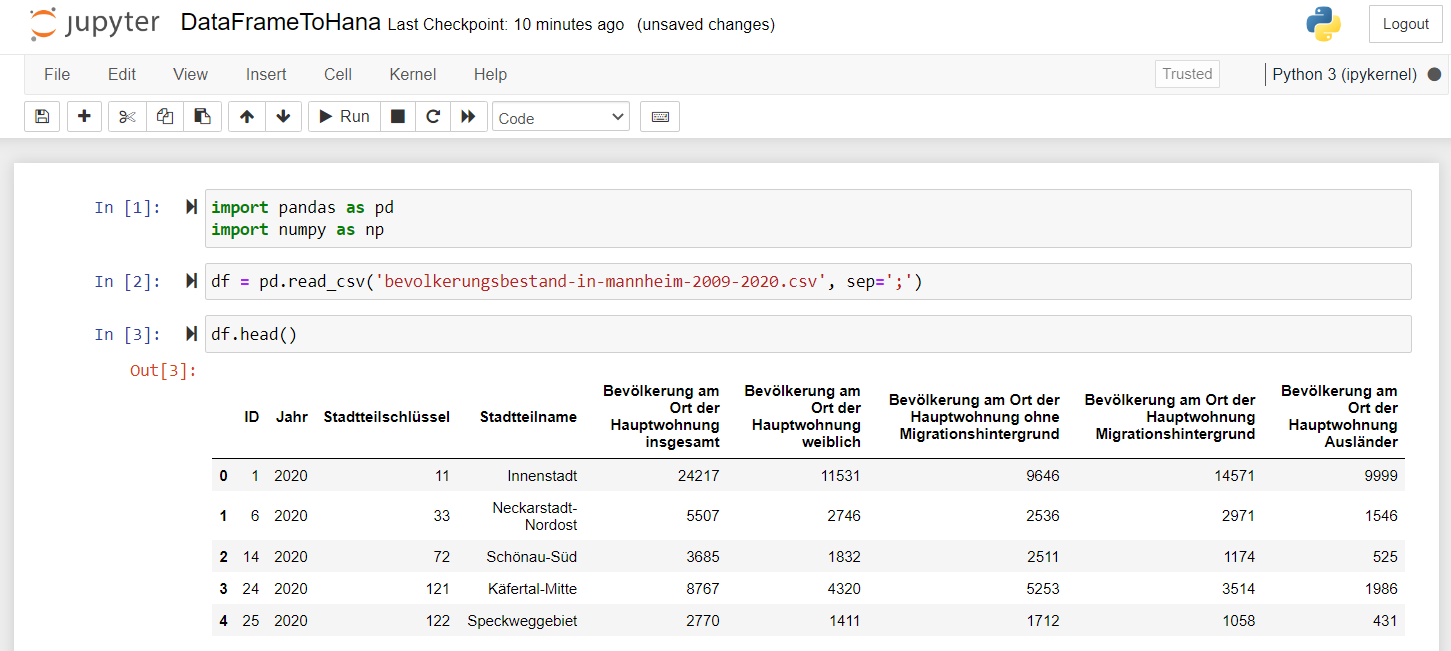
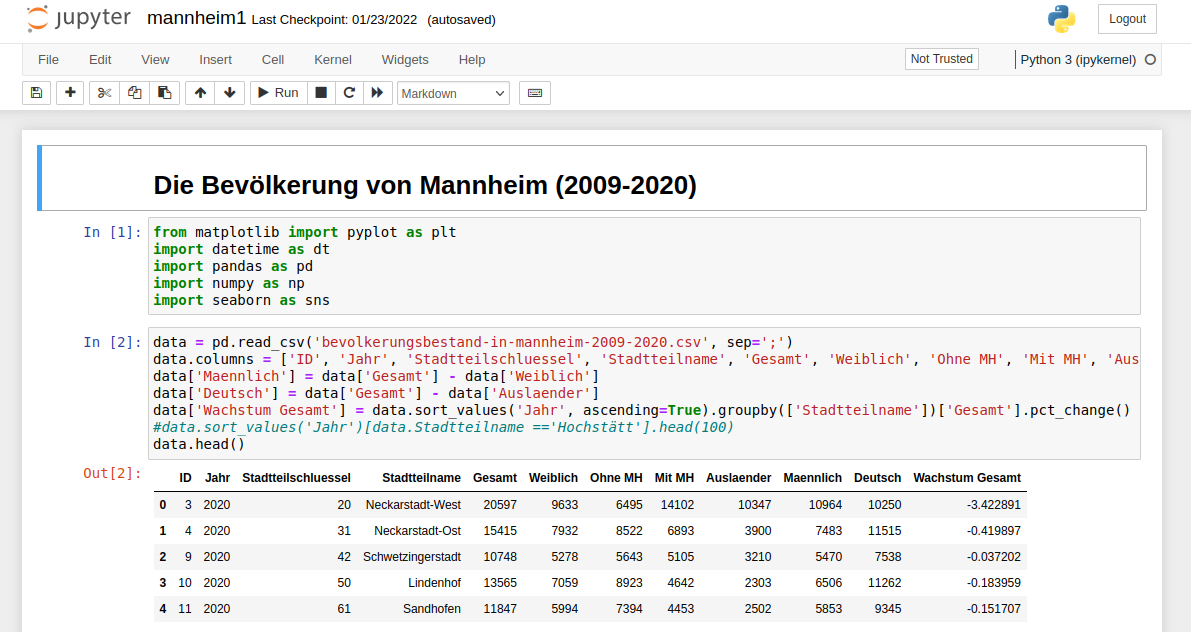
Mit Jupyter Notebook ist das Einlesen von Daten aus maschinenlesbaren Dateiformaten wie XML, JSON oder CSV ein Einzeiler.
Hier sieht man im ersten Befehlsblock das deklarieren der Abhängigkeiten. Im Zweiten Block wird die CSV-Datei in ein DataFrame eingelesen. Im dritten Block wird ein Teil des Datensatzes ausgegeben, damit man prüfen kann, ob alles stimmt.
Daten verarbeiten
Man könnte als nächstes nun mit dem DataFrame Operationen auf die Daten ausführen. Ich erspare mir das in diesem Beispiel, weil hier der Fokus auf das Zusammenspiel zwischen Jupyter Notebook und SAP HANA liegt.
Daten persistieren
Nun kommt der spannende Teil. Ich muss zugeben, ich habe eine Weile rumexperimentiert, bis ich herausgefunden habe, wie es funktioniert. SAP HANA hat ein paar Sicherheitsanforderungen, die bestimmte Parameter erforderlich machen. Das ist auch der eigentliche Grund, warum ich diesen Beitrag teile: Falls andere an einem ähnlichen Problem arbeiten, kann man mit diesem Beispiel ohne Hindernisse durchstarten.
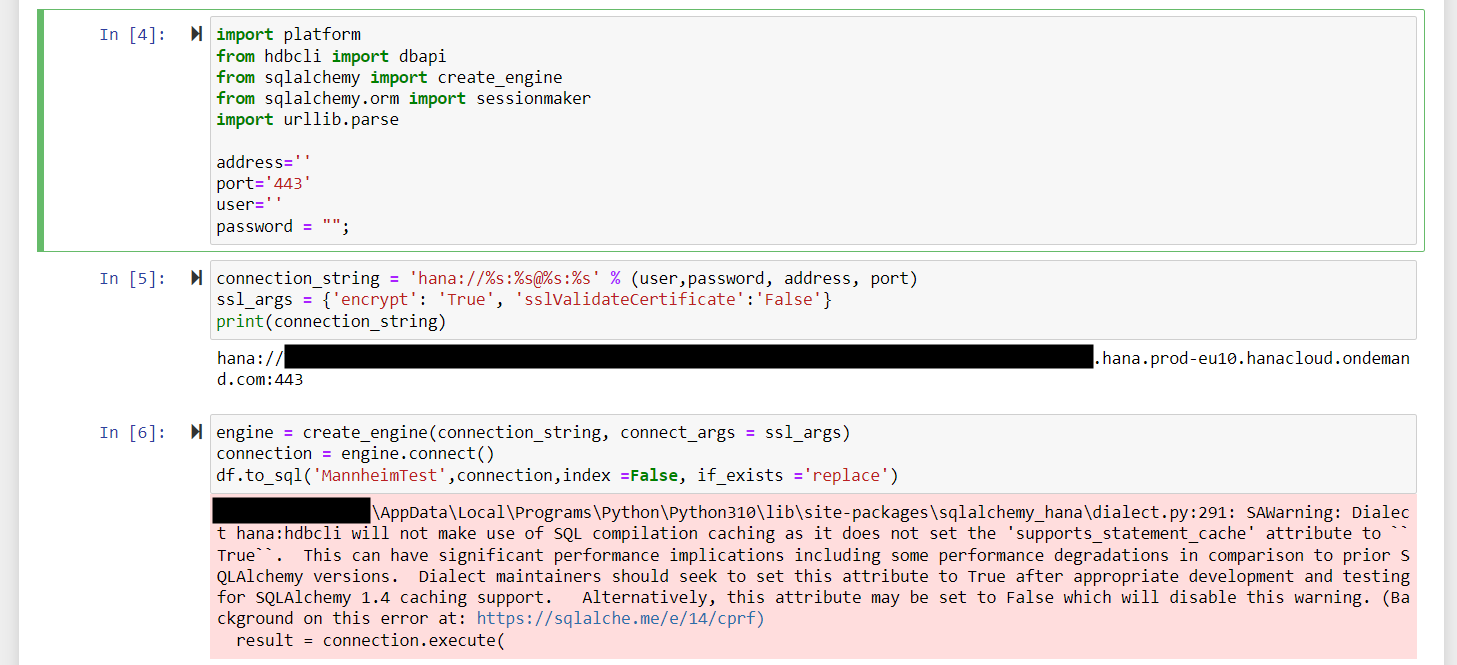
Mein Anspruch war, die von DataFrame bereit gestellte „to_sql“ Schnittstelle zu nutzen, um den Datensatz zu persistieren. Dadurch muss man sich keine Gedanken über die Datentypen machen und gelangt schneller ans Ziel.
Für nahtlose Integration werden die Bibliotheken „hdbcli“ und „sqlalchemy“ benötigt. Diese kann man sich mit dem Python Paketmanager pip installieren. Man benötigt die Zugangsdaten zur Datenbank. Es wird der Port, die Adresse, User und Passwort benötigt. Zu beachten ist, dass die Verbindung bei HANA ohne SSL nicht funktioniert. Das heißt, dass man auch die SSL-Argumente mit an die Verbindungsinformationen übergeben muss. Dies passiert in diesem Beispiel über die sqlalchemy-Bibliothek.
Man erzeugt eine Connection und übergibt dies dem „to_sql“ Befehl. Es gibt eine Warnmeldung. Dies kann man ignorieren. Auf diese Weise wird das DataFrame in der SAP HANA persistiert.
Daten prüfen
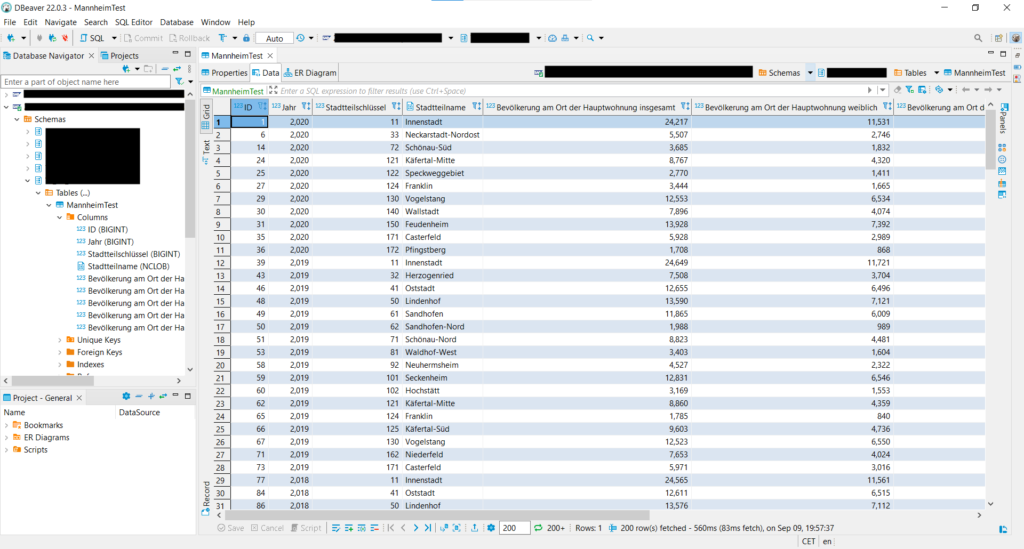
Mit DBeaver kann man sich in der Datenbank einloggen und prüfen, ob alles korrekt persistiert wurde. In diesem Fall sieht es sehr gut aus.
Ergebnis
Ich habe das Beispiel auch in Github geteilt. Das Repository kann man sich clonen, die Zugangsdaten in das Notebook eintragen und das Notebook ausführen. Falls dir dieser Beitrag nützlich war, bin ich dankbar für ein Star in dem Repository.
Die Möglichkeit, mit Jupyter Notebook Operationen auf SAP HANA durchzuführen ist ein mächtiges Werkzeug, was großes Potenzial hat. Im Kontext von Data-Science ist dieses Potenzial bisher nicht ausreichend geschöpft.
Ausblick
Was ich hier dargestellt habe ist natürlich nur die Vorarbeit für viele weitere potenzielle Anwendungsfälle. Ich habe die im obigen Beispiel erzeugte Tabelle mal aus Spaß in der HANA Instanz einer SAP Data Warehouse Cloud Instanz persistiert und mal eine kleine Pipeline aufgebaut.
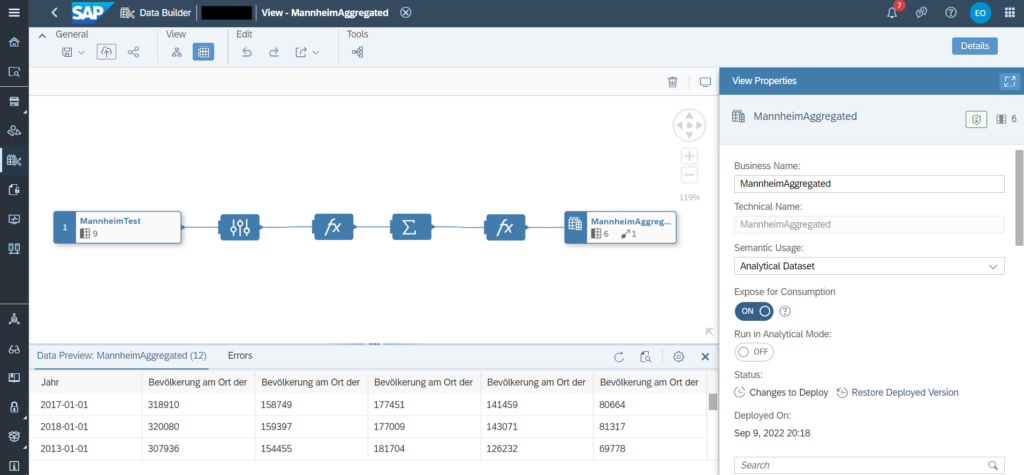
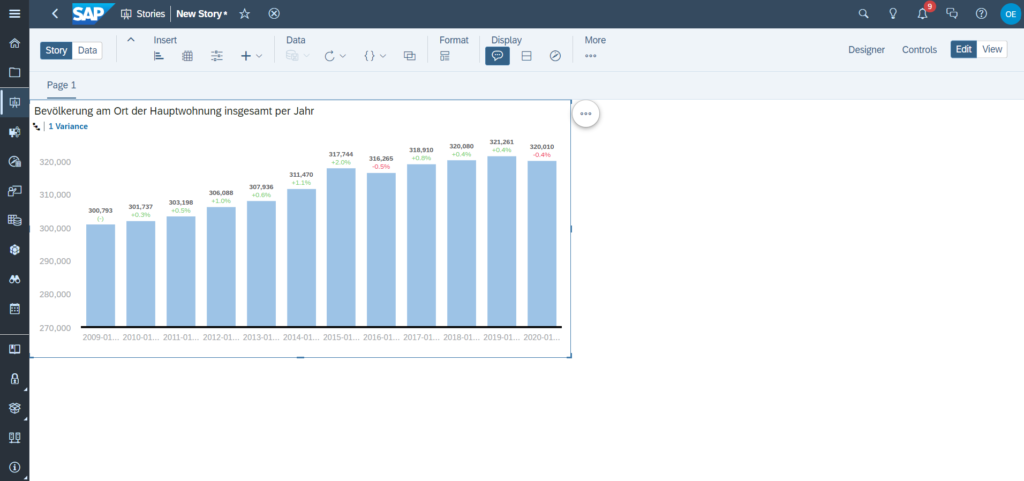
Der Anwendungsfall, für das ich diese Lösung benötigt habe, ist eine Data-Pipeline, bei der ich die Datenquelle nicht automatisiert an SAP Data Warehouse Cloud (DWC) übergeben konnte, weil sie in mehreren Excel Sheets rumlagen und die Daten sich regelmäßig verändern.
Mithilfe des Notebooks führe ich den Merge von mehreren Excel-Dateien aus meinem Dateisystem durch und persistiere sie in der DWC HANA Tabelle. In DWC kann ich über die Graphical Views oder Data Flows weitere Operationen durchführen, und zum Schluss in SAP Analytics Cloud visualisieren. Ich weiß nicht, ob ich dafür einen eigenen Beitrag schreiben werde. Aber fürs erste wars das!