Access-Logs sind in Hinsicht auf Datenschutz sehr kritisch. Man kann sie als Nutzer einer Webseite nicht deaktivieren und sie fallen unter den sensiblen Daten, da sie IP Adressen beinhalten und Rückschlüsse auf einzelne Menschen erlauben. Ich hatte bereits angekündigt, dass ich für einen bestimmten Zeitraum die Access-Logs meines Blogs untersuchen möchte. Ich möchte heute meine ersten Erkenntnisse darüber teilen.
Nginx Access Logs Analyse weiterlesenKategorie: Data Science
SAP Analytics Cloud
Heute präsentiere ich ein paar Eindrücke von Analysen, die ich in SAP Analytics Cloud (SAC) erstellt habe. Bei den Daten handelt es sich um die öffentlichen Bevölkerungsdaten von Mannheim. Mit diesem Prototypen soll man ein Eindruck davon gewinnen, wie SAC so aufgebaut ist und was damit alles möglich ist.
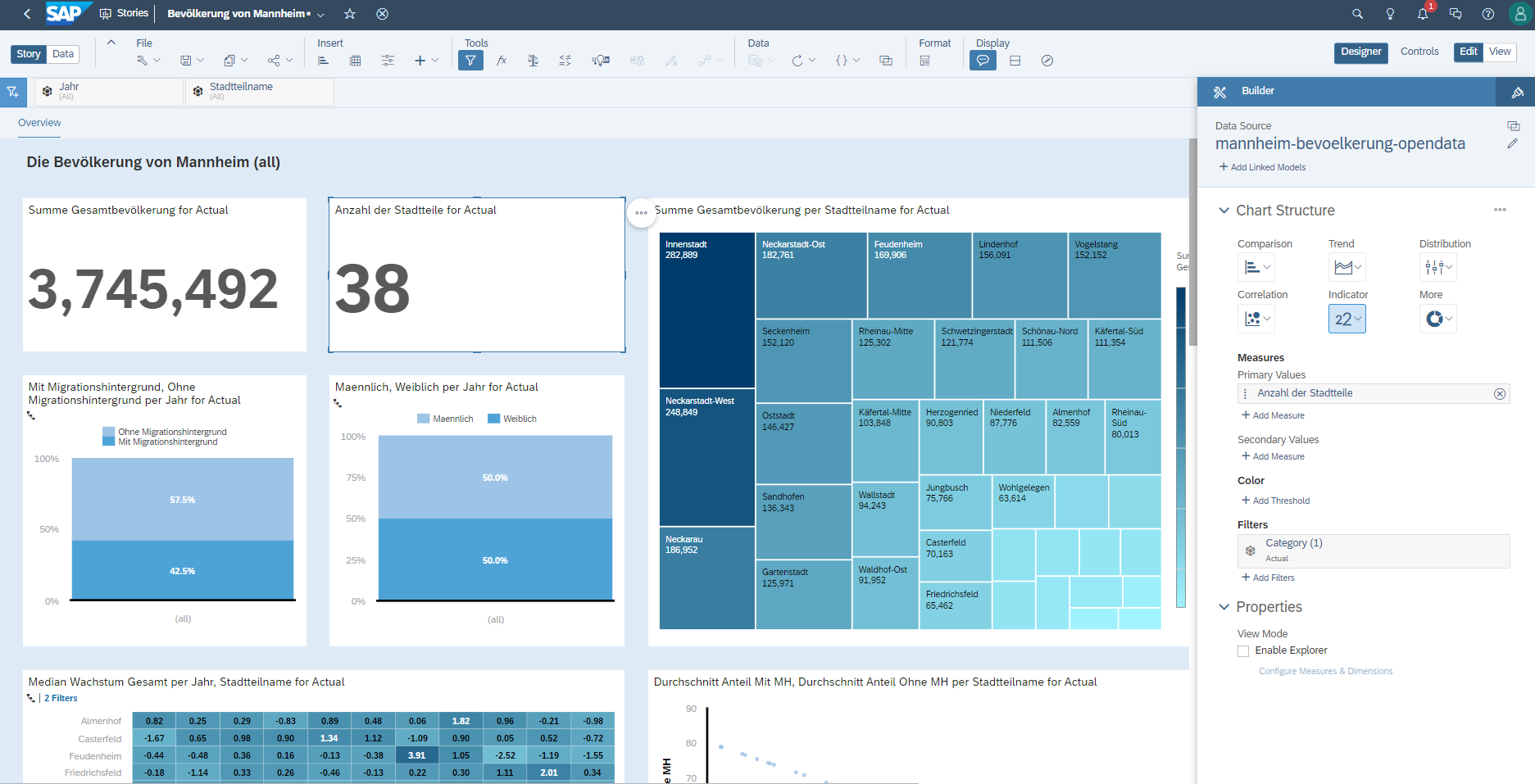
Ich war zum ersten Mal mit SAC vor ein paar Jahren im Rahmen eines Hochschulpraktikums bei SAP in Berührung gekommen. Ich hatte die Freude, bei dem Praktikum Elasticsearch/Kibana und SAC genauer zu untersuchen und die Vor- und Nachteile beider zu durchleuchten.
SAP Analytics Cloud weiterlesenDie Bevölkerung von Mannheim Teil 2
Ich hatte in einem vorherigen Post bereits die Bevölkerung von Mannheim analysiert. Ich hatte in der Analyse OpenSearch verwendet und bin auch relativ zufrieden mit dem Tool. OpenSearch hat jedoch seine Schwächen, wenn es darum geht, tatsächlich Analysen zu entwickeln. Die Rohdaten müssen auf verschiedene Arten aufbereitet werden, damit man wirklich zuverlässige Aggregationen und daraus folgender Analysen aufstellen kann. OpenSearch eignet sich gut für Live-Daten oder zum Konsumieren von Analysen (in Form von Reportings, Notifications, Alerts usw). Ich habe mich die letzten Wochen mit R und Jupyter Notebooks befasst und möchte eine verbesserte Darstellung hier bereit stellen. Jupyter basiert auf Python und man kann relativ schnell und einfach sehr interessante Graphen aufbauen.
Die Bevölkerung von Mannheim Teil 2 weiterlesenNginx: Access und Error Logs
Jeder Webserver hat Logs, das heißt eine Aufzeichnung von Aktivität. Für Apache und Nginx gibt es zwei Arten von Logs, Access Logs und Error Logs. Die Access Logs verzeichnen jeden Aufruf von Resourcen, wogegen Error Logs die Fehlermeldungen aufzeichnen, die beim Ausführen oder Liefern einer Ressource von statten gegangen sind.
Ich möchte im Rahmen einer Studie beide Arten von Logs näher anschauen und aufbereiten. Was kann man aus solchen Logs alles herausfinden? Ich habe aus diesem Grund meine Datenschutzerklärung im Impressum angepasst.
Im Rahmen einer Studie werden die Log-Dateien vom 14.Januar 2022 bis 01. Februar 2022 ausgewertet.
Nach Abschluss der Studie werden die Daten wieder gelöscht, die Auswertung wird anonymisiert hier im Blog veröffentlicht.
Bedeutung von Data-Science
Wir sind heute konfrontiert mit einer Flutwelle an Daten: Die Menge der Daten wächst jährlich exponentiell und wir haben zwei Möglichkeiten, mit dieser Welle umzugehen. Entweder ertrinken wir dabei, oder wir lernen, wie man schwimmt.
Daten sind das neue Öl: Sie müssen aus dem Boden geholt werden, sie müssen transportiert werden, sie müssen raffiniert werden, erst dann gewinnt Öl für uns Wert.
Der Google Chief Economist Hal Varian hat die Bedeutung von Data-Science folgendermaßen ausgedrückt.
The ability to take data – to be able to understand it, to process it, to extract value from it, to visualize it, to communicate it’s going to be a hugely important skill in the next decades, not only at the professional level but even at the educational level for elementary school kids, for high school kids, for college kids. Because now we really do have essentially free and ubiquitous data. So the complimentary scarce factor is the ability to understand that data and extract value from it.
I think statisticians are part of it, but it’s just a part. You also want to be able to visualize the data, communicate the data, and utilize it effectively. But I do think those skills – of being able to access, understand, and communicate the insights you get from data analysis – are going to be extremely important. Managers need to be able to access and understand the data themselves.
Google’s Chief Economist Hal Varian, The McKinsey Quarterly, January 2009
Mannheim Sozialatlas als CSV
Ich habe zuvor bereits erläutert, dass dieses Jahr ein Update des Mannheimer Sozialatlases herausgebracht wurde. Hier gehts zum Beitrag 2017 und 2021.
Was veröffentlicht wurde, sind PDF Dateien, in denen viele Graphen und Tabellen sind. Was mich als Datenanalyst jedoch genauso interessieren, sind Daten in einem offenen Format wie csv oder json. In diesen Formaten sind die Daten auch maschinell einfach zu verarbeiten. Ich habe eine kleine Anwendung geschrieben, um diese Daten auszulesen und als CSV zu exportieren.
Die beiden CSV Dateien finden sich hier und hier. Viel Spaß damit!
Motivation for Data-Science in Business Software
In this post, I want to talk about motivations for doing data-science. The reasons for doing data-science might seem obvious, but actual practice shows, that this topic is neglected.
Motivation for Data-Science in Business Software weiterlesenDie Bevölkerung von Mannheim Teil 1
Ich hatte vor kurzem bereits angekündigt, dass ich vermehrt Analysen von Open-Data Daten betreiben möchte. Ich habe zu diesem Anlass mir einfach mal die Bevölkerungsdaten von Mannheim angeschaut. Die Daten finden sich auch hier. Ich habe zusätzlich hier ein Upload der Rohdaten durchgeführt, damit sie für alle Fälle mal irgendwo wegen Gründen der Reproduzierbarkeit aufzufinden sind.
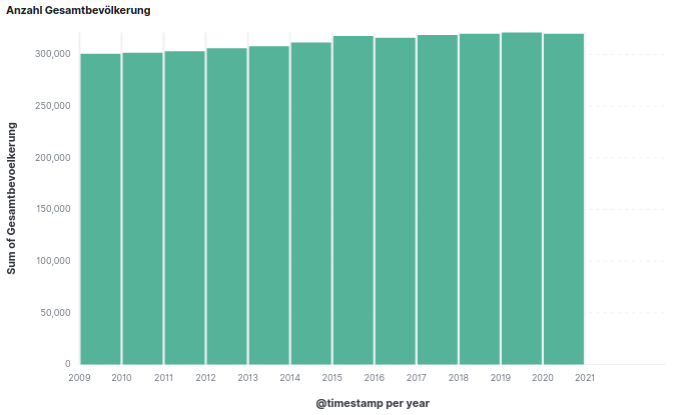
Die Anzahl der Gesamtbevölkerung von Mannheim betrug 2021 320.000. Seit 2010 ist dies ein Wachstum von durchschnittlich etwa 0,61%.
Die Bevölkerung von Mannheim Teil 1 weiterlesenOpen Data
Es gibt in den letzten Jahren eine große Initiative in Richtung Open Data. Das bedeutet, dass der Wunsch besteht, Daten öffentlich bereitzustellen, sodass diese nicht nur von einem Unternehmen oder einer begrenzten Nutzerschicht ausgewertet werden können, sondern von jedem Bürger. Open Data verfolgt zwei Kernziele:
- Transparenz: Das veröffentlichen von öffentlichen Daten, wie Ergebnisse von Wahlen ermöglicht das überprüfen von Wahlergebnissen.
- Forschung: Der Zugriff auf Daten von sozialen Netzwerken ermöglicht es soziale Fragen zu beantworten und Forschung in dieser Richtung zu betreiben.
Dagegen gibt es wiederum Gegenbewegungen, die Open Data verhindern versuchen. Unternehmen verdienen beispielsweise Geld mit den Daten und ihre Geschäftsmodelle bauen darauf auf. Es ist also verständlich, dass kein Interesse von diesen besteht, diese Daten zu veröffentlichen.
Als Data-Scientist möchte ich meine Werkzeuge und Möglichkeiten nutzen, vorhandene öffentliche Datensätze auszuwerten und diese in meinem Blog bereit zu stellen. Wenn nicht ich als Data-Scientist das mache, wer soll es dann machen? Mein erstes Projekt hierbei wird sein, die Bevölkerungszahl in Mannheim und der einzelnen Stadtteile zu analysieren.
Gene Sequencing und DNA Analyse
Erkenne dich selbst!
Inschrift am Apollotempel von Delphi
Letztes Jahr habe ich mich auf 23andme angemeldet und eine Speichelprobe gesendet, damit sie dort für mich einen DNA Test machen. Hier ist wie der Dienst sich selbst beschreibt:
Find out what your DNA says about you and your family.
See how your DNA breaks out across 2000+ regions worldwide. Discover DNA relatives from around the world. Share reports with family and friends Learn how your DNA influences your facial features, taste, smell and other traits.
Die Ergebnisse waren sehr interessant und erstaunlicherweise auch akkurat. Hier ist zum Beispiel, was bei mir bei der Ancestry raus kam:

Neben den ganzen Analysen und Traits fehlt aber eine entscheidende Sache: Die gesundheitlichen Aspekte. Man kann nicht herausfinden welche Erbkrankheiten man hat. Das ist auch verständlich: Nur der Arzt sollte dir so etwas mitteilen können, nachdem er die Daten begutachtet hat. Wenn man erfährt, dass man in einem bestimmten Alter eine bestimmte Krankheit bekommt, dann tritt bei den meisten vermutlich ein hysterisches Verhalten ein und man brauch eine Vertrauensperson wie einen Arzt, der das besänftigt. Vielleicht sollte man das aber auch nie herausfinden… Das ist für mich aber sehr unbefriedigend und ich habe beschlossen, das selbst in die Hand zu nehmen.
Gene Sequencing und DNA Analyse weiterlesen