Access-Logs sind in Hinsicht auf Datenschutz sehr kritisch. Man kann sie als Nutzer einer Webseite nicht deaktivieren und sie fallen unter den sensiblen Daten, da sie IP Adressen beinhalten und Rückschlüsse auf einzelne Menschen erlauben. Ich hatte bereits angekündigt, dass ich für einen bestimmten Zeitraum die Access-Logs meines Blogs untersuchen möchte. Ich möchte heute meine ersten Erkenntnisse darüber teilen.
Zur Verarbeitung der Daten habe ich ein Python Script in Jupyter Notebook geschrieben. Dieser liest die Log-Dateien Zeile für Zeile ein und erstellt daraus ein Pandas Dataframe. Im Folgenden ist ein Ausschnitt des Datensatzes mit den Spalten zu sehen.

Damit kann man nun alles mögliche machen. Mein erster Schritt war erst einmal, den Datensatz zu bereinigen. Es gibt Einträge, die keinen Sinn machen. Dafür habe ich einfach die Einträge mit den fehlerhaften HTTP Methods heraus gefiltert.
Was lernen wir nun aus dem Ganzen? Man kann mithilfe von Access Logs insbesondere auf die Fragen bezüglich der Besucher eingehen. Eine Zeile in den Access Logs ist ein Aufruf einer Ressource. Das heißt, dass mit jedem Seitenwechsel ein Eintrag erstellt wird. In meinem Blog werden etwa 2000 Aufrufe täglich getätigt. Von diesen 2000 Aufrufen sind etwa 350 eindeutige Besucher (eindeutige IP Adressen) pro Tag auszumachen.
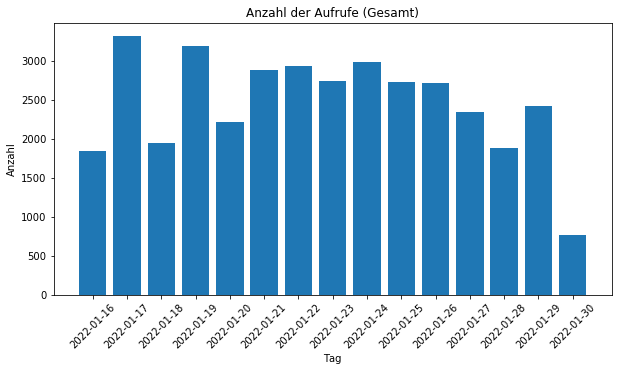
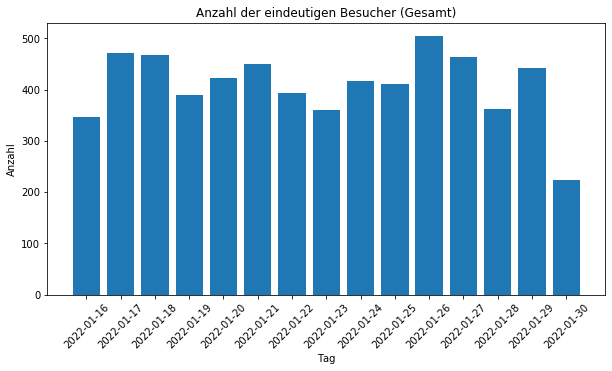
Tatsächlich besteht der Traffic zum größten Teil aus Crawlern und Bots. Aber wie filtert man nun die Crawler aus der Menge heraus? Ganz einfach: Man wählt nur die Besucher im Datensatz aus, die irgendwann mal ein CSS Stylesheets des Blogs geladen haben. Die meisten Crawler laden keine CSS Dateien herunter. Wenn wir das machen bekommen wir den folgenden Graphen.
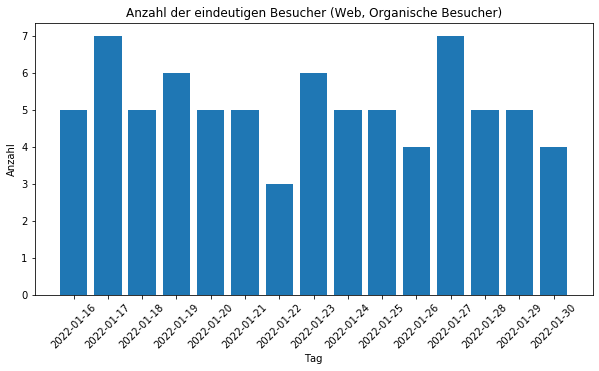
Fünf organische Besucher beglücken mein Blog täglich entweder über Suchmaschinen oder über den direkten Link. Man kann den Blog jedoch auch über ein Feed abonnieren. In jedem beliebigen RSS Reader kann man den Link des Blogges hinzufügen und wird laufend über Aktualisierungen informiert. Diese laden auch keine CSS herunter und können gesondert betrachtet werden.
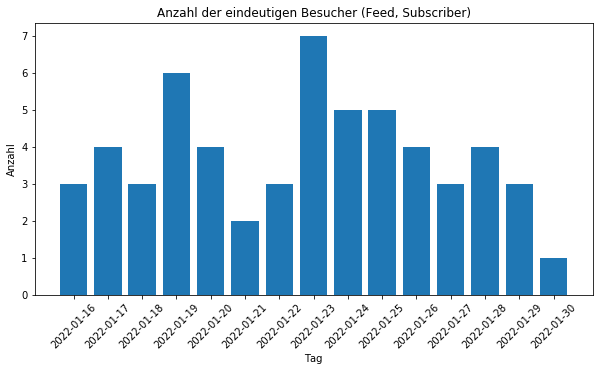
Es gibt 1-7 Abonnenten, die mein Blog abonniert haben. Die Zahlen erstaunen mich, da ich bisher keine Ahnung hatte, dass ich überhaupt Leser habe. Ich möchte damit die Gelegenheit nutzen und grüße dich herzlich, falls du einer dieser bist. Es ist aber natürlich auch nicht ausgeschlossen, dass auch diese organischen Besucher und Abonnenten in Wirklichkeit auch Crawler oder Bots sind. Das kann aus den Access Logs mithilfe meines kleinen Datensatzes nicht eindeutig ausgesagt werden.
Ich möchte damit auch zu einem vorläufigen Fazit kommen: Mein Blog ist klein und auch damit kann man einiges herausfinden. Die Auswertung von Access Logs kann ein Problem darstellen: Falls Analyselösungen (z.B. Google Analytics), Cloud-Provider (AWS, Azure, Google Cloud) oder Soziale Netze (z.B. über Facebook Like-Buttons) die Auswertung von Access Logs durchführen, können Besucher über viele Webseiten hinweg getrackt und Profile können erstellt werden. Man kann das Tracken über Access Logs nicht mithilfe von Browser-Lösungen wie uBlock Origin, NoScript oder Adblockern verhinden, da sie serverseitig bei jedem HTTP-Request durchgeführt werden. Das macht dieses Thema so sensibel. Dadurch bleibt einzig der Weg, diese über Gesetze zu regulieren – was ja bekanntlich mithilfe der DSGVO gewünscht ist.
Im nächsten Teil möchte ich auf die Error-Logs eingehen. In den Error-Logs werden HTTP Fehlermeldungen gesammelt. Was können wir aus den Error-Logs lernen? Wie können wir sie uns am Besten zu Nutze machen?