Heute präsentiere ich ein paar Eindrücke von Analysen, die ich in SAP Analytics Cloud (SAC) erstellt habe. Bei den Daten handelt es sich um die öffentlichen Bevölkerungsdaten von Mannheim. Mit diesem Prototypen soll man ein Eindruck davon gewinnen, wie SAC so aufgebaut ist und was damit alles möglich ist.
Ich war zum ersten Mal mit SAC vor ein paar Jahren im Rahmen eines Hochschulpraktikums bei SAP in Berührung gekommen. Ich hatte die Freude, bei dem Praktikum Elasticsearch/Kibana und SAC genauer zu untersuchen und die Vor- und Nachteile beider zu durchleuchten.
Kritiker bemängeln oft, dass SAC zu langsam ist. Das liegt aber meiner Meinung nach nicht daran, weil SAC schlecht ist, sondern dass man diese Anwendung falsch nutzt. Ein Kernaspekt bei Data-Pipeline Lösungen ist, dass sie ein anderes Datenformat nutzen, als relationale Datenbanken. Personen, die vorher nur mit relationalen Datenbanken (wie Postgres, Mysql, S/4HANA) gearbeitet haben, kommen anfangs nicht ganz mit dem Paradigma von NoSQL Datenbanken klar. Ein Datenmodell in dritter Normalform verhindert Redundanzen, aber sie sind sehr schlecht für Aggregation über Daten. Elasticsearch und SAC arbeiten beide mit einem ähnlichen Paradigma. Wir müssen über Daten sehr effizient aggregieren können. Dies erreicht man mit gezielten Redundanzen im Datensatz. Ist das Datenformat richtig angelegt, so ist SAC vergleichbar gut wie Pendant-Produkte wie Elasticsearch/Kibana oder Opensearch. SAC hat viele Funktionen. Im Folgenden sieht man ein paar dieser Funktionalitäten, die in der Menüleiste angezeigt werden. Ich werde mich heute mit „Datasets“ und „Stories“ beschäftigen.
In der „Datasets“ App kann man Daten in SAC importieren und sie später für Stories nutzen. „Datasets“ ist für einfachere Datenmodelle geeignet, bei dem es vielleicht schnell gehen muss. Ich nutze sie gerne für meine Prototypen, da ich meistens einfache vorverarbeite CSV Dateien importiere und nutze. Für komplexere Anwendungsfälle eignet sich die „Modeler“-App eher.
Man kann sowohl CSV/Excel Dateien importieren, als auch externe Datenquellen nutzen. Datenquellen werden dann gebraucht, falls man zum Beispiel Live-Daten analysieren möchte oder eine Analyse im Rahmen einer Big-Data-Pipeline betreiben möchte.
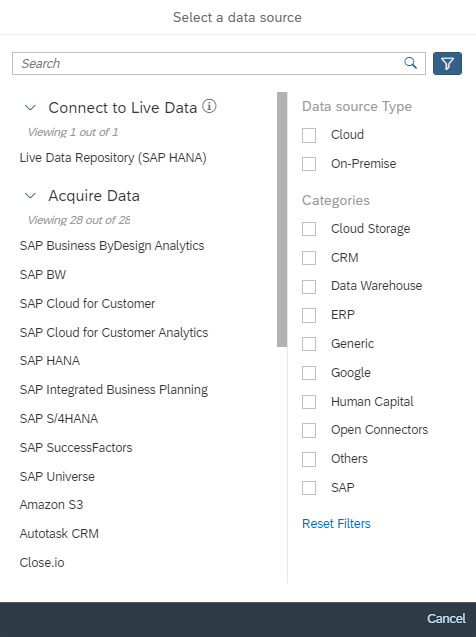
Es wird eine große Palette an SAP und Nicht-SAP Datenquellen unterstützt. Hier ist eine vollständige Auflistung, was alles möglich ist.
Nachdem man die Daten importiert hat, sieht man einen Ausschnitt der Daten und hat ähnlich wie in anderen Data-Science Lösungen die Möglichkeit, die Daten zu verändern. Es ist möglich „Transforms“ anzuwenden, sodass man neue Spalten erstellt, ändert oder löscht. Es sind auch Berechnungen über verschiedene Spalten und Dimensionen möglich (z.B. die für Berechnung von Wachstumsraten).
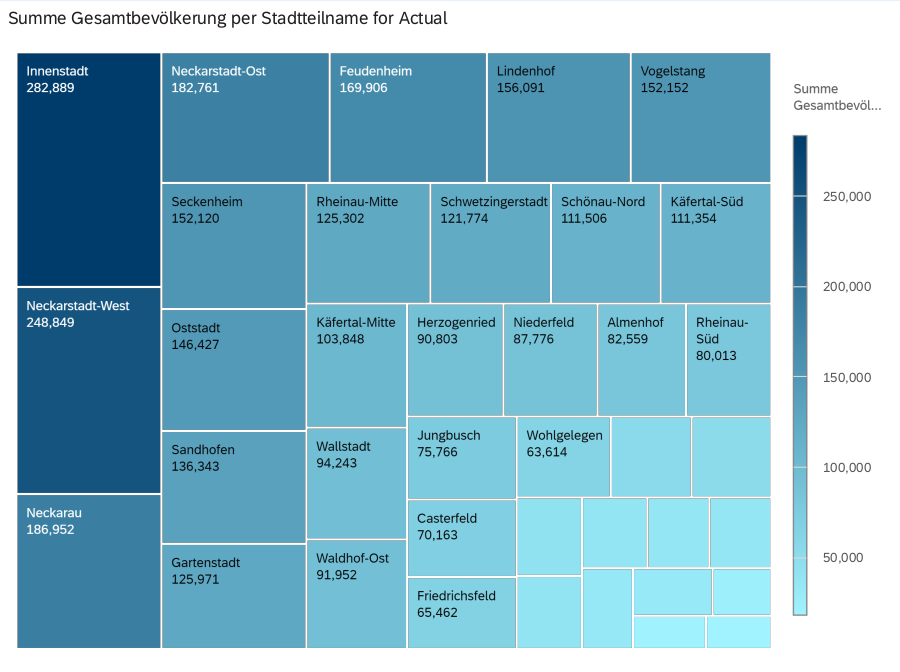
Ich möchte im Folgenden ein paar Ausschnitte aus einer Story teilen. Ähnliche Graphen sind bereits aus meiner Opensearch und Jupyter Notebooks Analysen bekannt.

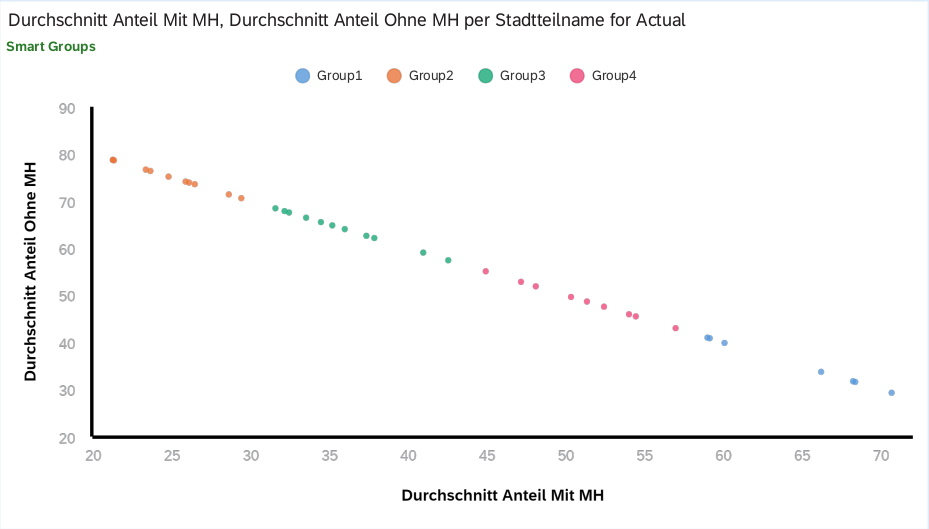
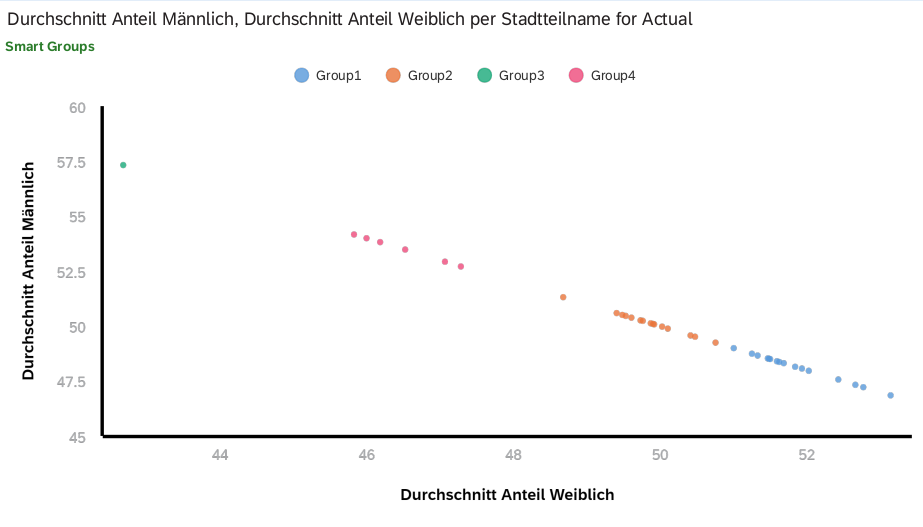
Eine sehr angenehme Sache bei SAC ist das Smart Grouping bei den Streudiagrammen. In den folgenden Graphen wurde diese Funktion genutzt, um die Stadtteile zu gruppieren. Diese Gruppen können für weitere Analysen in Betracht gezogen werden.
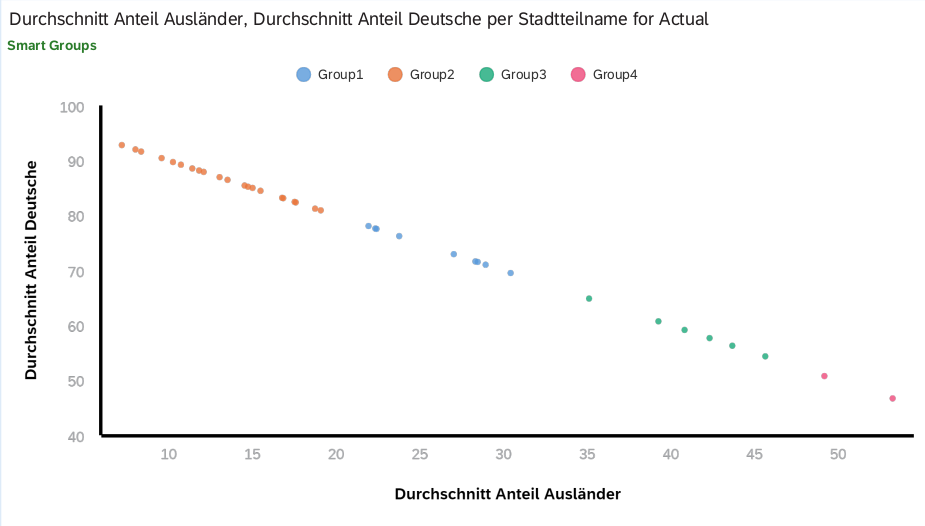
Der folgende Graph war für mich sehr überraschend. Erstaunlicherweise unterscheiden sich die Stadtteile bei der Verteilung der Geschlechter.
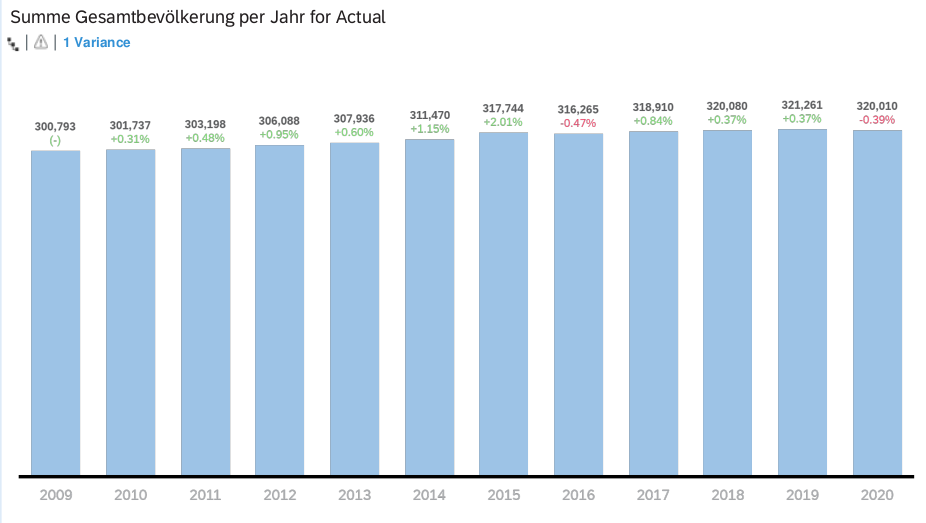
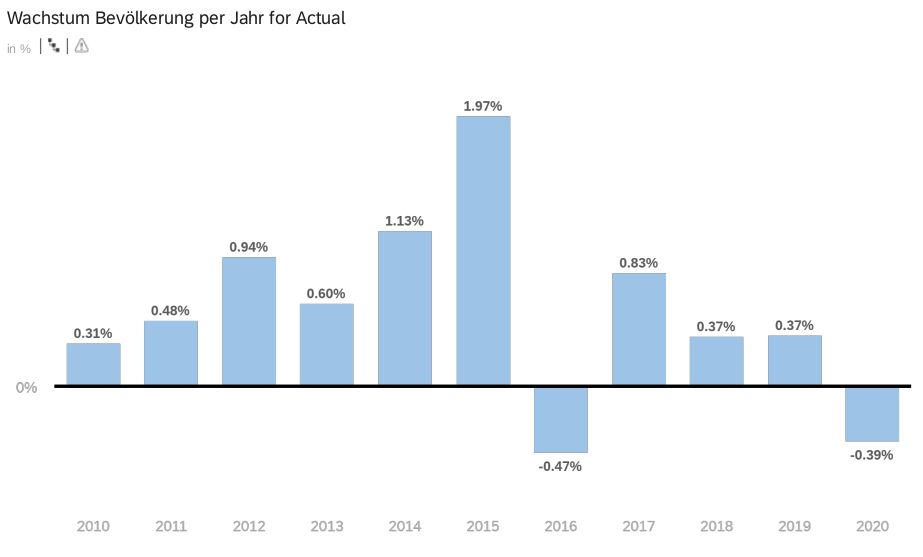
Im Folgenden sind nur die absoluten Zahlen und Wachstumszahlen der Gesamtbevölkerung dargestellt.
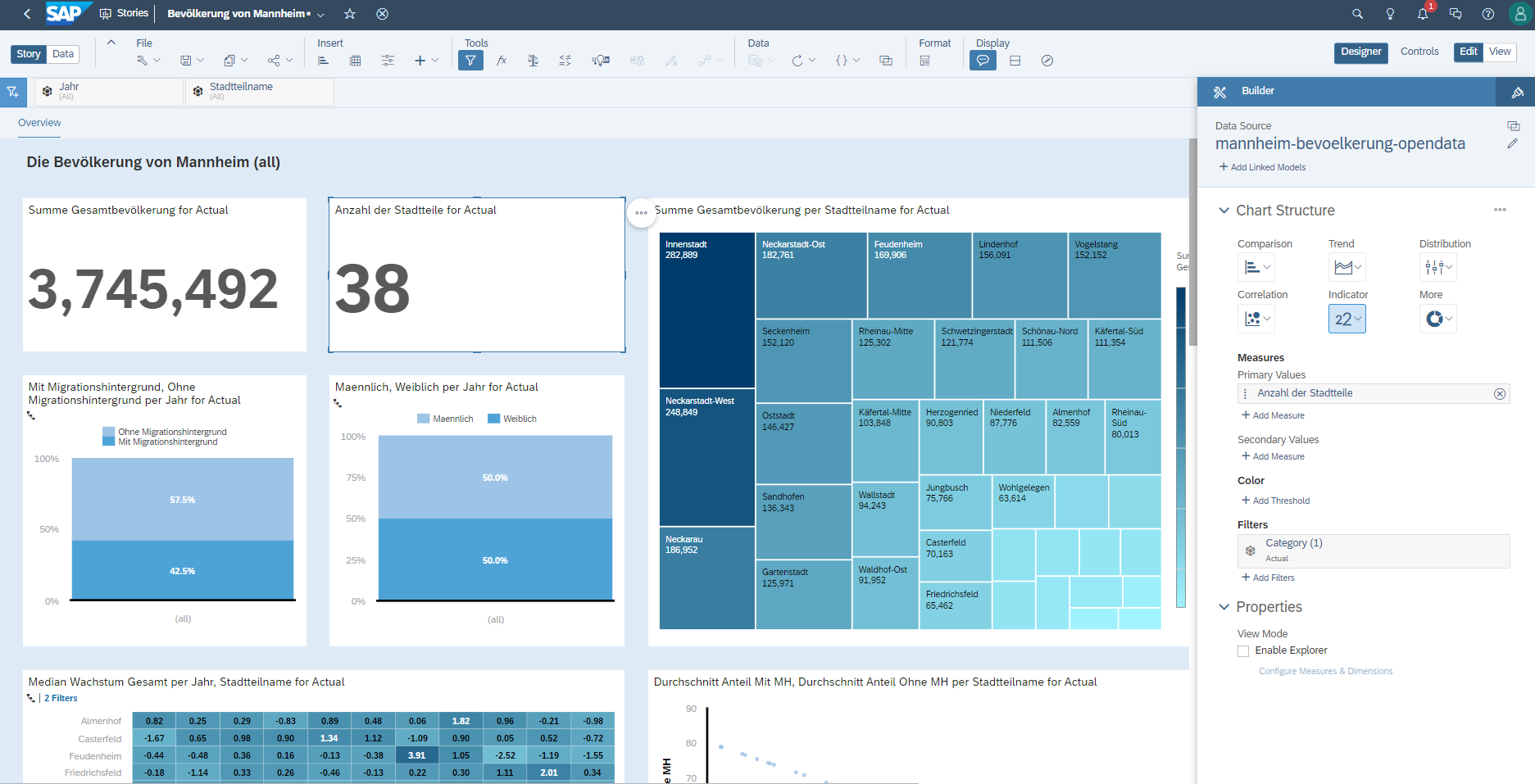
Hier kann die exportierte SAC Story als Ganzes betrachtet werden.
Mein Fazit: Ich finde SAC zur Visualisierung von Datenanalysen sehr gut. Ich bin sehr zufrieden mit den Möglichkeiten, die SAC mit einfachen Mausklicks und ohne Programmieraufwand ermöglicht. Anders als in OpenSearch ist es hier möglich, die bereits importierten Daten über ein User-Interface zu bearbeiten, sodass eventuell ganz neue Berechnungen und Erkenntnisse möglich sind. Auch die Palette an verschiedenen Diagrammen, und die Möglichkeit darüber hinaus in R neue Diagramme zu entwickeln, ist sehr vorteilhaft.