Ich habe vor kurzer Zeit meine Home Assistant Helium Integration veröffentlicht. Das Plugin erlaubt, Daten aus der Solana Blockchain direkt in Home Assistant anzuzeigen. Ich bin involviert in verschiedenen Themen. Aber ich habe bislang noch nie mit Daten oder Anwendungen auf einer Blockchain gearbeitet.
Ich habe meine ersten Daten extrahiert und in der Integration eingebaut. Ich möchte in diesem Beitrag die Möglichkeiten und Herausforderungen rund um das Extrahieren von Daten aus der Blockchain erläutern.
Solana Blockchain
Man kann sich Solana eigentlich wie eine große Datenbank vorstellen. Die Daten werden in Accounts gespeichert. Es gibt Programme (auch bekannt als „Smart Contracts“), verschiedene Arten von Accounts wie Program Accounts und Token Accounts, in denen die Informationen organisiert werden können. Das Speichern von Daten auf der Blockchain kostet eine geringe Gebühr, die „Rent“ genannt wird.
Der Vorteil von der Solana Blockchain ist, dass man so sein ganzes Backend im Grunde in der Blockchain betreiben kann und das Ganze performant laufen soll. Wo ist aber der Haken? Der Haken liegt darin, dass man sogenannte „Endpoints“ benötigt. Ein Endpoint ist ein Server, der mit der Blockchain synchronisiert ist und Daten daraus über die Solana APIs bereitstellt. Man kann selber so ein Endpoint betreiben, die Kosten für Speicherplatz und Traffic fallen somit zusätzlich zum Rent an.
Account
Die Wichtigste Einheit stellt ein Account dar. Ein Account wird durch ein Public-Key identifiziert, was gleichzeitig auch die Adresse des Accounts ist. Accounts können Programme und Daten speichern, die aufgerufen und ausgeführt werden.
Das Extrahieren von Daten fokussiert sich daher auf dieses Element. Daten werden nicht als Text abgespeichert, sondern Binär. Das sorgt dafür, dass der Speicherplatz auf der Blockchain effizient genutzt werden kann. Es werden tatsächlich nur die Informationen gespeichert, die zur Interpretierung der Daten nötig sind, statt beispielsweise ganze Zeichenketten, die JSON enthalten.
Datentypen
Dafür bedient sich Solana den Datentypen in C oder Rust. Die zu speichernden Objekte werden in C oder Rust mit ihren jeweiligen Datentypen definiert, als Byte serialisiert und auf der Blockchain persistiert. Hier ist ein Beispiel für eine Datenstruktur, die als Objekt persistiert werden kann.
pub struct Example {
pub address: Pubkey,
pub rewards: u64,
pub config: u16,
pub list: Vec<Option<u64>>,
pub seed: u8,
}In dieser Struktur ist eine Palette an mehreren Attributen enthalten. In Rust sind u64, u16 und u8 die Bezeichnung für Ganzzahlen ohne Vorzeichen.
Kleines Beispiel: Benötigt man eine Zahl ohne Vorzeichen mit weniger als 255. In diesem Fall würde man ein Attribut mit dem Datentyp „u8“ nutzen. Dadurch können Alle Zahlen von 0 bis 255 abgedeckt werden.
Objekte wie Listen oder andere können ebenfalls persistiert werden. Die Serialisierung/Deserialisierung sollte hierbei jedoch klar definiert sein, da dies ansonsten zu Problemen führen kann.
Solana Python SDK
Ich nutze das Solana Python SDK, um Abfragen gegen Endpoints durchzuführen. Für Python Entwickler ist die Einstiegshürde damit gering.
endpoint = "https://api.mainnet-beta.solana.com"
client = AsyncClient(endpoint)
res = await client.is_connected()
print(res)Eine Verbindung mit dem Endpoint lässt sich mit diesem Befehl durchführen. Das „client“ Objekt steht nun für weitere Abfragen zur Verfügung.
Es handelt sich bei diesem SDK jedoch um keine offizielle Bibliothek von Solana. Daher werden nicht alle Funktionalitäten unterstützt. Wenn man alle Funktionen von Solana nutzen möchte, muss man sich die nötigen Schnittstellen selber bauen, oder andere Möglichkeiten nutzen.
Account abfragen
Es gibt verschiedene Arten von Schnittstellen, um Inhalte abzufragen.
address = "BL5PB11X18ZtAVBhqMZDUV9huv7312onwvUAgCVKX9ic"
account_info = await client.get_account_info(Pubkey.from_string(address))
print(account_info)Das Ergebnis sieht wie folgt aus.
GetAccountInfoResp {
context: RpcResponseContext {
slot: 193827990,
api_version: Some(
"1.13.7",
),
},
value: Some(
Account(
Account {
lamports: 2088000,
data.len: 160,
owner: 1azyuavdMyvsivtNxPoz6SucD18eDHeXzFCUPq5XU7w,
executable: false,
rent_epoch: 0,
data: ae0ec7d9ce6c9a321f6b83620c8aa17cf48ec5a22b8ae291466b33fa4b08a9d8ffaf216a7a36e7710b928785a39f4d33d3f85eb6785151ea6d2773c207ff6beb,
},
),
),
}Es wird ein Objekt zurück gegeben, welches als „value“ den Account beinhaltet. Für die weitere Analyse ist das Feld „data“ und „data.len“ interessant. Man kann nun probieren, die Daten auszugehen.
print(account_info.value.data)b"\xae\x0e\xc7\xd9\xcel\x9a2\x1fk\x83b\x0c\x8a\xa1|\xf4\x8e\xc5\xa2+\x8a\xe2\x91Fk3\xfaK\x08\xa9\xd8\xff\xaf!jz6\xe7q\x0b\x92\x87\x85\xa3\x9fM3\xd3\xf8^\xb6xQQ\xeam's\xc2\x07\xffk\xeb\x07\x91Ud\xa2!\xf5\x1e\x80)\xf8d\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\xff)\xf8d\x00\x00\x00\x00\xff\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00"Wir sehen hier nämlich keine Daten in Klartext, die für die weitere Verarbeitung relevant sind. Im „data“-Feld gibt es Binärdaten, die eine Länge von 160 haben.
Structs definieren
Damit man diese Daten nun auslesen kann, benötigt man weitere Informationen. Es muss das Objekt bekannt sein, von dem diese Daten kommen. Um das heraus zu finden, muss man wissen, woher dieses Datum kommt. Wir können dies über den „Owner“ heraus finden.
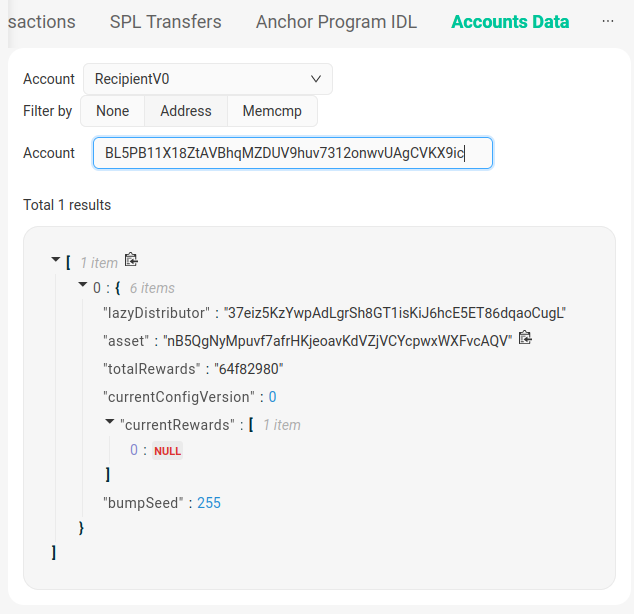
Beim Owner sehen wir, dass dieser Account dem Account „RecipientV0“ zugeordnet ist. Die Datenstruktur findet man im Tab daneben, unter den „Achor Program IDL„.
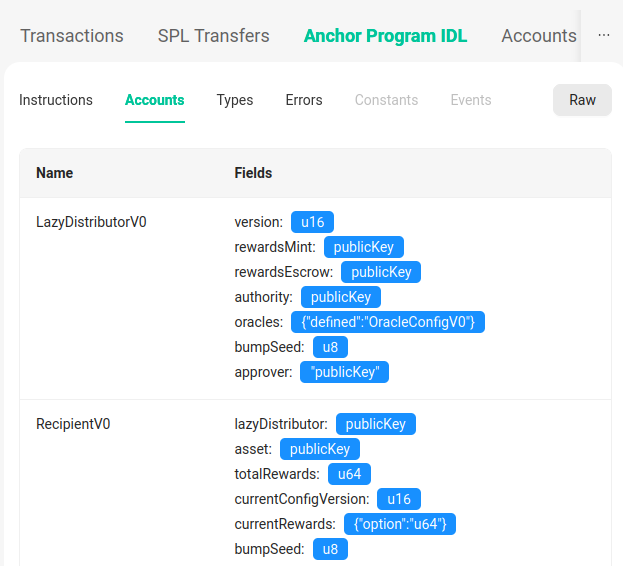
IDL steht für Interface Definition Language und ist stellt die JSON-Repräsentation der Schnittstellen eines Objektes dar. Mit diesen Informationen ist es möglich, die Daten wieder zu lesen.
Datenstruktur
Die genaue Datenstruktur heraus zu finden kann eine Herausforderung sein. Gegebenenfalls muss viel getestet werden, bis man das präzise Datenmodell gefunden hat. Das Struct dieses Beispiels findet sich auch als Struct Code in der ursprünglichen Rust Bibliothek, aus der dieses IDL ausgerollt wurde.
Auch wenn es in Rust einfach aussieht, ändert sich die genaue Struktur in anderen Programmiersprachen wie Python. Die folgende Python Struktur war am Ende die korrekte Struktur, die zum Ergebnis geführt hat.
from construct import Struct, Int64ul, Int32ul, Int16ul, Bytes, Adapter, Byte
# Little Endian
class OptionU64(Adapter):
def _decode(self, obj, context, path):
if obj[0] == 0:
return None
else:
return int.from_bytes(obj[1:], 'little')
def _encode(self, obj, context, path):
if obj is None:
return b'\x00' + b'\x00'*8
else:
return b'\x01' + obj.to_bytes(8, 'little')
RecipientV0 = Struct(
"identifier" / Bytes(8),
"lazy_distributor" / Bytes(32), # publicKey
"asset" / Bytes(32), # publicKey
"total_rewards" / Int64ul, # u64
"current_config_version" / Int16ul, # u16
"current_rewards" / OptionU64(Bytes(5)), # Vec<Option<u64>>
"bump_seed" / Byte, # u8
)Was neu dazu gekommen ist, ist ein weiterer Wert am Anfang des Structs, was ich hier als „identifier“ bezeichne. Wenn man die native Bibliothek in Rust nutzt, muss man dies nicht beachten, aber da ich hier die Daten ohne die Zunahme einer Bibliothek extrahiere, muss ich hier 8 Bytes hinzufügen, um diesen Identifikator zu beachten.
Einfache Listen können sehr anspruchsvoll in der Umsetzung sein. Wie ein Objekt tatsächlich interpretiert wird, ist sehr Programmiersprachenabhängig. In diesem Fall muss man testen, bis man die korrekte Umwandlung findet. Ich bin kein Experte in der Deserialisierung von Binärdaten. Ich habe mich hier auch intensiv an Hilfe von ChatGPT-4 bedient.
Die Bytereihenfolge ist ebenfalls relevant. Es gibt „Little-Endian“ und „Big-Endian“. Der Unterschied ist dabei, dass die Werte von unterschiedlicher Richtung ausgelesen werden. Beim Little-Endian wäre eine Hexadezimale Folge 0x12345678 abgespeichert als „78 56 34 12“. Beim „Big-Endian“ wäre die gleiche Folge dagegen abgespeichert als „12 34 56 78“. Dieser Unterschied hat teilweise historische Gründe und welches umgesetzt ist, muss ebenfalls durch ausprobieren herausgefunden werden. Bei den Integer Werten steht das „l“ am Ende des Datentypes „Int16ul“ für den Little-Endian. Ersetzt man Buchstaben mit „b“, wird der Wert mit dem Big-Endian interpretiert.
Auslesen
Nun kann man die Struktur nutzen, um die Daten auszulesen.
parsed = RecipientV0.parse(account_info.value.data)
print(parsed)Container(identifier=b'\xae\x0e\xc7\xd9\xcel\x9a2', lazy_distributor=b'\x1fk\x83b\x0c\x8a\xa1|\xf4\x8e\xc5\xa2+\x8a\xe2\x91Fk3\xfaK\x08\xa9\xd8\xff\xaf!jz6\xe7q', asset=b"\x0b\x92\x87\x85\xa3\x9fM3\xd3\xf8^\xb6xQQ\xeam's\xc2\x07\xffk\xeb\x07\x91Ud\xa2!\xf5\x1e", total_rewards=1693985152, current_config_version=0, current_rewards=0, bump_seed=255)Wenn man die Daten hier mit den Inhalten aus der Abbildung 1 vergleicht, sieht man, dass einiges hier bereits sehr gut aussieht. Aber es sind immernoch Inhalte in Binärer Darstellung vorhanden. Diese kann man folgendermaßen in ein String umwandeln.
string_data = base58.b58encode(parsed.lazy_distributor).decode("utf-8")
print(string_data)'37eiz5KzYwpAdLgrSh8GT1isKiJ6hcE5ET86dqaoCugL'Dadurch bekommt man exakt den Wert, der bereits in Abbildung 1 zu sehen ist, und der hier erwartet war. Auf diese Weise wurden Binäre Daten in der Blockchain wieder in nutzbare Daten in Python umgewandelt.
Möglichkeiten zum Debugging
Was ich hier aufgezeigt habe ist der beste Pfad. Bis ich persönlich zu diesem Ergebnis gekommen bin, habe ich Aufwand reinstecken müssen. Ich möchte auch ein paar Mittel zeigen, wie man mit Binärdaten arbeitet.
Base58 / Base64
Wenn Binärdaten serialisiert werden und abgespeichert werden, müssen zuverlässig zu einer Zeichenkette umgewandelt werden. Dies geschieht über Base58 oder Base64 encoder. Das „data“ Feld aus der API Abfrage beinhaltet das Datum in Base64 encoded:
ae0ec7d9ce6c9a321f6b83620c8aa17cf48ec5a22b8ae291466b33fa4b08a9d8ffaf216a7a36e7710b928785a39f4d33d3f85eb6785151ea6d2773c207ff6bebOftmals lässt sich im Vornherein aussagen, ob es sich um Base58 oder Base64 handelt. Base58 beinhaltet keine Zeichen wie „O“/“0“, „L“/“I“ die miteinander verwechselt werden können.
import base58
data = account_info.value.data
lazy_distributor = data[8:40]
print(lazy_distributor)
decoded_lazy_distributor = base58.b58encode(lazy_distributor)
print(decoded_lazy_distributor.decode())b'\x1fk\x83b\x0c\x8a\xa1|\xf4\x8e\xc5\xa2+\x8a\xe2\x91Fk3\xfaK\x08\xa9\xd8\xff\xaf!jz6\xe7q'
37eiz5KzYwpAdLgrSh8GT1isKiJ6hcE5ET86dqaoCugLDieses Beispiel zeigt, wie einzelne Bytes aus den Binärdaten extrahiert werden können. In Python wählt man den Abschnitt einfach mit den eckigen Klammern und bekommt so ein Teil der Daten. Hier sieht man auch das Encoden und Decoden anhang eines kleinen Beispiels.
Erwartete Ergebnisse
Weiß man im Vornherein, was im Ergebnis zu erwarten ist, so stochert man nicht Blind in den Binärdaten, bis man was nutzbares findet, sondern kann gezielter suchen.
Ich weiß aus Abbildung 1, dass ich ein Wert namens „lazy_distributor“ mit dem Inhalt „37eiz5KzYwpAdLgrSh8GT1isKiJ6hcE5ET86dqaoCugL“ haben muss. Ich kann nun einfach diese Zeichenkette in einen Binärwert umwandeln.
pk_expectation = Pubkey.from_string('37eiz5KzYwpAdLgrSh8GT1isKiJ6hcE5ET86dqaoCugL')
pk_expectation_bytes = bytes(pk_expectation)
print(pk_expectation_bytes)b'\x1fk\x83b\x0c\x8a\xa1|\xf4\x8e\xc5\xa2+\x8a\xe2\x91Fk3\xfaK\x08\xa9\xd8\xff\xaf!jz6\xe7q'Dies ist die Ausgabe von dem Datenfeld:
b"\xae\x0e\xc7\xd9\xcel\x9a2\x1fk\x83b\x0c\x8a\xa1|\xf4\x8e\xc5\xa2+\x8a\xe2\x91Fk3\xfaK\x08\xa9\xd8\xff\xaf!jz6\xe7q\x0b\x92\x87\x85\xa3\x9fM3\xd3\xf8^\xb6xQQ\xeam's\xc2\x07\xffk\xeb\x07\x91Ud\xa2!\xf5\x1e\x80)\xf8d\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\xff)\xf8d\x00\x00\x00\x00\xff\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00"Exakt diese Binäre Wert findet sich auch im ursprünglichen Datenfeld. Wir wissen dadurch, dass sich das Feld „lazy_distributor“ nicht direkt am Anfang, sondern ein klein wenig danach befindet. Wo genau es anfängt, kann man wieder so herausfinden, dass man ein Teil des Datums ausgibt.
binary_data[8:]b"\x1fk\x83b\x0c\x8a\xa1|\xf4\x8e\xc5\xa2+\x8a\xe2\x91Fk3\xfaK\x08\xa9\xd8\xff\xaf!jz6\xe7q\x0b\x92\x87\x85\xa3\x9fM3\xd3\xf8^\xb6xQQ\xeam's\xc2\x07\xffk\xeb\x07\x91Ud\xa2!\xf5\x1e\x80)\xf8d\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\xff)\xf8d\x00\x00\x00\x00\xff\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00"Hieraus kann man folgern, dass die ersten 8 Bytes zu einem anderen Zweck verwendet werden. Ich weiß, dass dies zur Identifikation des Objektes dient. In Rust mit der offiziellen Solana Bibliothek muss man dies nicht berücksichtigen. In Python dagegen muss dies berücksichtigt werden.
Fazit
Ich habe hier anhand eines kleinen Beispiels gezeigt, wie man Daten aus der Solana Blockchain extrahiert und wie man eine korrekte Deserialisierung hinbekommt. Wenn man außerhalb der nativen Programmiersprache entwickelt (z.B. in Python statt Rust), so muss man sich auf zusätzliche Herausforderungen gefasst machen.
Ich selber habe damit auch meine ersten Erfahrungen mit Blockchain Anwendungen gesammelt. Anwendungen, die auf Solana laufen, stehen mit der Herausforderung konfrontiert, das Datenmodell in der Blockchain so zu persistieren, dass am Ende eine effiziente Verarbeitung erfolgen kann. Ist dies nicht der Fall, so kann die Performance der Anwendung leiden.
Entwickler stehen bei Blockchain-Daten mit der Herausforderung der Serialisierung und Deserialisierung konfrontiert. Mit einer Python Bibliothek, die mit Rust kompatible Datenstrukturen anbietet, wäre eine Umsetzung der Datenauslesung vermutlich deutlich einfacher.
Meine persönliche Meinung ist, dass die Solana Blockchain nicht immer die beste Wahl ist, wenn es darum geht, ein Backend zu betreiben. Für Anwendungen, die hohe Anforderungen an Transparenz und Verteiltheit haben, ist eine Infrastruktur auf der Blockchain eine gute Lösung. Die Kosten und Performance sind aber nicht immer besser, als in Nicht-Blockchain Anwendungen. Den Anwendungsfall, den ich beispielsweise versucht habe umzusetzen, könnte man mit in einem kleinen Rahmen mit einer einfachen Web-Anwendung mit Datenbank in viel kürzerer Zeit und mit deutlich weniger HTTP Abfragen durchführen. Man würde aber die Transparenz und Verteiltheit einbüßen.
In Hinsicht auf Kosten muss man sich bei größeren Anwendungen ein Endpoint mieten, was den Kosten von Webservern nahe kommt, weil ähnliche Anforderungen an Traffic und Speicherplatz gebraucht werden. Wo es aber definitiv ein Vorteil bietet ist in der Skalierbarkeit. Anwendungen lassen sich durch weitere Endpoints schnell und einfach skalieren.